- TensorTeach's Newsletter
- Posts
- Visual Reasoning in Multimodal LLMs, Long Reasoning Benchmark Launched, Medical AI Gains New Data Engine
Visual Reasoning in Multimodal LLMs, Long Reasoning Benchmark Launched, Medical AI Gains New Data Engine
TensorTeach AI
August 29, 2025
How Multimodal LLMs Solve Image Tasks: A Lens on Visual Grounding, Task Reasoning, and Answer Decoding

Image from arXiv paper.
What’s the research question?
How do multimodal large language models (LLMs) internally process and integrate visual and textual inputs across their layers to perform image-related tasks?
What did the authors do?
The authors developed a novel probing framework to dissect the internal workings of multimodal LLMs:
They trained linear classifiers (probes) on token embeddings at each layer to predict visual categories, using a fixed anchor question to generate consistent embeddings.
They tested the probes on images from the same classes but with systematically varied prompts, including lexical changes, semantic negation, and different answer formats.
They evaluated how well each layer captured different computational stages: visual grounding (aligning image regions with tokens), lexical integration (combining visual and textual info), semantic reasoning, and answer decoding.
What did they find?
The study revealed a clear, stage-wise internal organization across multiple multimodal LLMs:
Early layers specialize in visual grounding, aligning visual features with language tokens.
Middle layers support lexical integration and semantic reasoning, combining visual and textual information to understand the task.
Final layers focus on answer decoding, generating task-specific outputs.
This layered structure is consistent across different models and variations in visual tokenization, instruction tuning data, and pretraining corpora.
However, the exact layer allocation to each stage shifts depending on the base LLM architecture; for example, LLaVA-1.5 and LLaVA-Next-LLaMA-3 share similar stages, while Qwen2-VL reallocates layers to extend reasoning capabilities.
Why does this matter?
Understanding how multimodal LLMs process visual and language inputs internally is crucial for improving their design, interpretability, and robustness. This work provides:
A unified, layer-wise perspective on the internal stages of multimodal reasoning, helping researchers diagnose and enhance model behavior.
A lightweight, model-agnostic probing framework that can be applied to other multimodal architectures to study their representation dynamics.
Insights that can guide the development of more effective multimodal models by aligning architectural choices with the natural stages of visual and semantic processing.
Key Points
Introduced a probing framework to analyze internal stages of multimodal LLMs layer-by-layer.
Identified a consistent stage-wise structure: visual grounding → lexical/semantic integration → answer decoding.
Found that stage allocation varies with model architecture but maintains a general pattern across models.
Provides insights to improve multimodal model interpretability and design.
LongReasonArena: A Long Reasoning Benchmark for Large Language Models
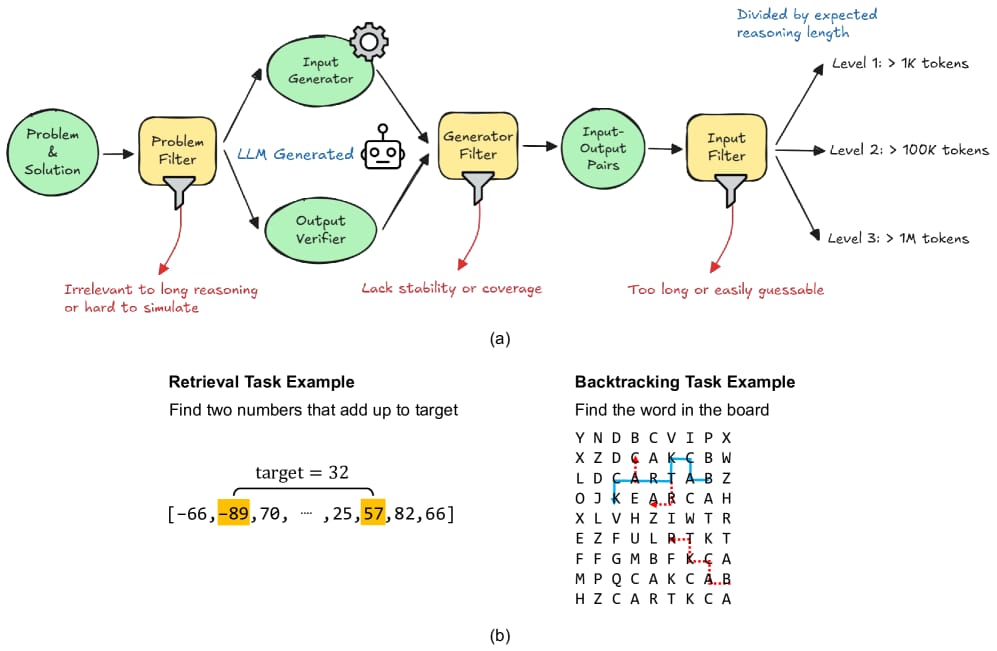
Image from arXiv paper.
What’s the research question?
How can we effectively evaluate the long reasoning capabilities of large language models (LLMs)?
What did the authors do?
The authors developed LongReasonArena, a comprehensive benchmark designed to test LLMs on long reasoning tasks that involve executing multi-step algorithms with up to 1 million tokens of reasoning. Their approach included:
Selecting algorithmic problems from LeetCode, filtering out those solvable by simple heuristics to focus on challenging tasks.
Generating diverse and difficult inputs using Qwen2.5-Coder-32B-Instruct.
Categorizing tasks into three levels based on the number of execution lines: Level 1 (~1K tokens), Level 2 (~100K tokens), and Level 3 (~1M tokens).
Evaluating models by having them produce answers enclosed in \\boxed{}, which are then verified for correctness.
Testing 12 models of various sizes and reasoning abilities, both via API and on local hardware.
What did they find?
Key findings from the evaluation include:
Reasoning models outperformed non-reasoning models across the board, highlighting the importance of dedicated reasoning capabilities.
Performance declined sharply as task difficulty increased, with the most challenging Level 3 tasks seeing only 7.5% accuracy by Deepseek-R1.
Accuracy decreased linearly with the logarithm of the expected number of reasoning steps, with a strong correlation (R2 > 0.9) across reasoning models.
Retrieval and backtracking—core operations in algorithm execution—were identified as major challenges, with models struggling to perform these operations effectively over long contexts.
Why does this matter?
LongReasonArena fills a critical gap in evaluating how well LLMs can handle long, complex reasoning tasks that mirror real-world algorithmic and cognitive challenges. By focusing on execution of multi-step algorithms and key operations like retrieval and backtracking, it provides a scalable and controllable framework to diagnose strengths and weaknesses of current models. This benchmark can guide future research toward developing LLMs with more robust long-term reasoning and problem-solving abilities, which are essential for applications requiring deep understanding, planning, and complex decision-making.
Key Points
Introduces LongReasonArena, a benchmark for long reasoning tasks up to 1 million tokens.
Focuses on algorithmic problems requiring multi-step execution and key cognitive operations.
Reasoning models outperform non-reasoning models but struggle with very long tasks.
Highlights retrieval and backtracking as key challenges in long-context reasoning.
MedGR2: Breaking the Data Barrier for Medical Reasoning via Generative Reward Learning

Image from arXiv paper.
What’s the research question?
How can integrating generative reward learning and self-improving data synthesis enhance the generalization and robustness of medical vision-language models?
What did the authors do?
The authors introduced MedGR2, a novel framework designed to improve medical vision-language reasoning by combining three key components:
Multimodal Data Synthesis: A controllable generator (Gθ) creates diverse, clinically meaningful visual question-answer (VQA) triplets (image, question, answer) using prompt-driven, step-by-step, and meta-cognitive generation techniques.
Adaptive Reward Modeling: A reward model (Rϕ) evaluates each triplet based on factual accuracy, reasoning soundness, and relevance to instructions. It is trained on a small set of expert preferences and continually refined using generated data.
Reinforcement Learning Policy: A reasoning policy (πθ) is trained in two stages: an initial supervised fine-tuning (SFT) on high-quality data, followed by a Group Relative Policy Optimization (GRPO) phase that maximizes a composite reward to improve reasoning and factual correctness.
What did they find?
MedGR2 achieved state-of-the-art performance on the OmniMedVQA benchmark, reaching 87.45% accuracy after combining SFT and GRPO. Notably, even without reinforcement learning, SFT on generated data outperformed all baselines, including models trained on large human-curated datasets. The synergy of high-quality synthetic data and adaptive reward learning led to significant improvements in cross-modality and cross-task generalization. The compact 7-billion-parameter MedGR2 model outperformed larger models like Qwen2-VL-72B by +19.7% in accuracy. Ablation studies confirmed that both data quality and reinforcement learning were crucial for optimal results.
Limitations include the reliance on the quality of synthetic data and reward models, which may require careful tuning for different medical domains.
Why does this matter?
MedGR2 demonstrates that scalable, high-quality synthetic data combined with adaptive reward modeling can substantially enhance the generalization and robustness of medical vision-language models. Its parameter efficiency and strong performance challenge the common assumption that larger models are always better. By generating clinically meaningful data and iteratively refining reward signals, MedGR2 offers a promising pathway for deploying more capable, data-efficient medical AI systems in real-world clinical settings—potentially improving diagnostic accuracy, decision support, and patient outcomes.
Key Points
Introduces MedGR2, a framework combining generative data synthesis, reward modeling, and reinforcement learning for medical vision-language reasoning.
Uses a controllable generator to create diverse, clinically relevant VQA triplets with prompt-driven methods.
Employs an adaptive reward model refined through expert preferences and generated data to evaluate factuality and reasoning.
Achieves state-of-the-art accuracy on the OmniMedVQA benchmark with a parameter-efficient 7B model, outperforming larger counterparts.
A Graph Talks, But Who’s Listening? Rethinking Evaluations for Graph-Language Models

Image from arXiv paper.
What’s the research question?
How effective are current evaluation benchmarks for Graph-Language Models (GLMs) in assessing their ability to perform multimodal reasoning?
What did the authors do?
The authors investigated the capabilities of two recent GLM architectures, TEA-GLM and GraphToken, by:
Evaluating their performance on six diverse datasets, comparing against unimodal baselines such as Graph Neural Networks (GNNs) and soft-prompted Large Language Models (LLMs).
Introducing CLeGR, a new synthetic benchmark designed specifically to test multimodal reasoning, with two subsets: CLeGR-Facts (focused on retrieval tasks) and CLeGR-Reasoning (focused on multi-hop reasoning).
Conducting probing analyses to understand what information graph encoders capture and how LLMs function as decoders within these models.
What did they find?
The key findings include:
High performance of GLMs on CLeGR-Facts, indicating they can handle retrieval tasks well.
Struggles with CLeGR-Reasoning, where GLMs performed similarly to unimodal baselines, suggesting limited multimodal reasoning ability.
Probing revealed that graph encoders captured all task-relevant information in datasets with sufficient structural information, with LLMs effectively acting as decoders.
Current benchmarks may overestimate GLMs’ multimodal reasoning capabilities by allowing solutions based on unimodal information.
Why does this matter?
This work highlights a critical gap in how we evaluate Graph-Language Models: existing benchmarks may not accurately measure their true multimodal reasoning abilities. By introducing CLeGR, the authors provide a more targeted tool to assess and improve these models. The findings suggest that future research should focus on developing more sophisticated evaluation methods and architectural innovations that better leverage graph structures for cross-modal reasoning, ultimately advancing AI systems that can understand and reason across diverse modalities like language, vision, and graphs. This has broad implications for building more intelligent, multimodal AI agents capable of complex reasoning in real-world applications.
Key Points
Current benchmarks may overstate GLMs’ multimodal reasoning capabilities by not challenging their ability to integrate modalities.
The new CLeGR benchmark isolates multimodal reasoning, revealing limitations of existing GLMs.
Graph encoders capture all relevant info in structurally rich datasets, but GLMs struggle with multi-hop reasoning tasks.
Calls for more nuanced evaluation and architectural designs to fully exploit graph-language multimodal reasoning.
Survey of Specialized Large Language Model
What’s the research question?
How have specialized large language models (LLMs) evolved from simple domain adaptation to native architectures, and what are their impacts across various professional domains?
What did the authors do?
This survey analyzed 48 specialized LLMs developed between 2022 and 2025, focusing on their architectural innovations and domain-specific applications. Key methodological steps included:
Categorizing models based on dataset specialization, training architecture, evaluation standards, and modular enhancements.
Reviewing model architectures, training regimes, and evaluation methodologies through expert assessments and domain-specific benchmarks.
Grouping models by professional domains such as healthcare, finance, and legal, and comparing their performance using metrics like F1 scores, accuracy, and perplexity.
Assessing innovations like sparse computation, multimodal integration, and retrieval-augmented generation for their impact on efficiency and effectiveness.
What did they find?
Specialized LLMs consistently outperformed general-purpose models in domain-specific tasks, demonstrating significant performance gains:
Med-PaLM 2 achieved state-of-the-art results on the USMLE medical exam, highlighting its medical expertise.
BloombergGPT excelled in entity recognition and sentiment analysis within financial texts.
Innovations such as mixture-of-LoRAs and expert routing reduced memory usage and increased inference speed, making models more practical for real-world deployment.
Evaluation standards evolved to include expert assessments and multidimensional benchmarks, ensuring models meet the nuanced needs of professional domains.
Limitations include the challenge of balancing specialization with generalization and the need for extensive domain-specific data.
Why does this matter?
This survey underscores the transformative potential of specialized LLMs in high-stakes professional fields. By integrating architectural innovations and domain-specific data, these models can deliver more accurate, reliable, and efficient performance than general-purpose counterparts. This has significant implications for:
Healthcare: Improving diagnostic tools, medical question-answering, and personalized treatment recommendations.
Finance: Enhancing entity recognition, sentiment analysis, and risk assessment in complex financial texts.
Legal: Streamlining document analysis, contract review, and legal research.
It provides a roadmap for future research and deployment, emphasizing the importance of rigorous evaluation and tailored model design to meet the demanding requirements of professional domains.
Key Points
Specialized LLMs outperform general models in domain-specific benchmarks like medical exams and financial analysis.
Architectural innovations such as sparse computation and multimodal integration improve efficiency and versatility.
Evaluation standards now include expert assessments and multidimensional benchmarks for real-world relevance.
The survey offers a comprehensive roadmap for developing and deploying specialized LLMs in high-stakes fields.