- TensorTeach's Newsletter
- Posts
- Visual AI Evolves: Unified Vision-Language Models, Reasoning with Tools, & Why Multimodal LLMs Still Struggle to “See” Like Us
Visual AI Evolves: Unified Vision-Language Models, Reasoning with Tools, & Why Multimodal LLMs Still Struggle to “See” Like Us
TensorTeach AI
July 25, 2025
Advancing Visual Large Language Model for Multi-granular Versatile Perception
What’s the research question?
Can a unified framework improve the versatility and performance of visual perception tasks across different granularities (like detection and segmentation) and instruction types in a single model?
What did the authors do?
The authors developed MVP-LM, a novel large language model (LLM) architecture that integrates multiple visual perception tasks at different granularities into one unified system. Key components include:
Image encoder: Uses a Swin-Base Transformer to extract visual features from input images.
Connector module: Aligns visual features with language tokens for joint reasoning.
Language model: Based on Phi-1.5, generates text summaries and instruction embeddings.
Multi-granularity decoder: Produces bounding boxes (detection) and segmentation masks (segmentation) by iteratively cross-attending with multi-scale visual features.
During training, they unified diverse datasets into a common format using a CoT-inspired strategy that combines task descriptions, instructions, and responses. Responses follow a 'thinking-then-perceiving' approach, prepending image captions to summaries. Visual queries are dynamically generated by selecting top N visual features most similar to instruction embeddings, then combined with base query vectors from the language model. Loss functions include next-token prediction for the LLM, cross-entropy and Dice loss for masks, GIoU for boxes, and word-based perception losses. During inference, only the final outputs are used for prediction.
What did they find?
MVP-LM achieved state-of-the-art results on multiple perception benchmarks:
56.1 Panoptic Quality (PQ) and 66.8 cIoU on COCO-Panoptic segmentation.
83.6/85.1 on RefCOCO referring expression comprehension.
Ablation studies showed:
Joint training on multiple datasets improved cross-task generalization.
The 'thinking-then-perceiving' response format enhanced both sentence- and word-level perception.
Using 100 queries balanced performance and computational efficiency.
Query selection strategies influenced performance differently across datasets.
Limitations include the complexity of dynamic query generation and potential computational costs, which may be addressed in future work.
Why does this matter?
This work demonstrates that a single, unified visual-language model can outperform specialized models by effectively handling diverse perception tasks at multiple granularities. The innovative query generation and 'thinking-then-perceiving' strategies enable more flexible and generalizable visual-linguistic reasoning, paving the way for versatile AI systems capable of understanding and interacting with complex visual environments through natural language instructions. Such advancements could benefit applications in robotics, autonomous agents, and multimodal AI assistants that require integrated perception and language understanding.
Key Points
Unified MVP-LM integrates detection and segmentation tasks at multiple granularities into one model.
Dynamic visual query generation based on instruction similarity improves task-specific focus.
'Thinking-then-perceiving' response format enhances perception at sentence and word levels.
Joint training across datasets boosts cross-task generalization and versatility.
Thinking Isn’t an Illusion: Overcoming the Limitations of Reasoning Models via Tool Augmentations
What’s the research question?
Can external tools enhance the reasoning abilities of Large Reasoning Models (LRMs) compared to standard Large Language Models (LLMs)?
What did the authors do?
The authors conducted a systematic evaluation of how augmenting LRMs and LLMs with external tools affects their reasoning performance:
Equipped both LRMs and LLMs with two types of tools: a Python interpreter for executing generated code and a scratchpad for external memory of intermediate steps.
Tested models on Apple’s “thinking-illusion” benchmark, which includes four puzzles of varying difficulty: Hanoi Tower, Checker Jumping, River Crossing, and Blocks World.
Generated step-by-step solutions for each puzzle, verifying correctness and comparing performance with and without tool use across different puzzle sizes and configurations.
What did they find?
External tool augmentation significantly improved reasoning performance, especially for LRMs:
LRMs with tools achieved around 80% accuracy on River Crossing and Blocks World, compared to less than 20% without tools.
In Hanoi Tower, LRMs with tools reached perfect accuracy even for large N, demonstrating strong scalability.
Some tasks like Checker Jumping remained unsolvable for all models, indicating limits of current approaches.
The effectiveness of tools depended on the base model’s strength; LRMs benefited more than LLMs from augmentation.
Program of Thought (PoT) framework was the most effective tool augmentation method, followed by the scratchpad; Think-and-Execute showed minimal gains.
Why does this matter?
This work challenges the idea that reasoning is an illusion by showing that LRMs can significantly improve their reasoning capabilities through external tools. It highlights the importance of tool use in evaluating and unlocking the true potential of large models for complex, multi-step reasoning tasks. The findings suggest that future research should focus on developing more sophisticated tools and better integration methods to enhance model reasoning, paving the way for more capable AI systems that can solve real-world problems requiring logical inference and planning.
Key Points
External tools like code interpreters and memory modules boost reasoning accuracy in LRMs.
LRMs with tools outperform LLMs without tools by large margins on challenging puzzles.
Tool augmentation methods vary in effectiveness; Program of Thought is particularly powerful.
Results encourage integrating diverse tools to enhance AI reasoning and problem-solving capabilities.
Pixels, Patterns, but No Poetry: To See The World like Humans A Preliminary
What’s the research question?
Can Multimodal Large Language Models (MLLMs) perceive and interpret visual information as humans do?
What did the authors do?
The authors investigated the visual perception capabilities of MLLMs by introducing a new benchmark called the Turing Eye Test (TET), which evaluates models on four challenging visual tasks:
HiddenText: Detecting obscured text in images.
3DCaptcha: Recognizing distorted 3D CAPTCHA images.
ColorBlind: Interpreting images designed for color vision deficiency.
ChineseLigatures: Deciphering complex Chinese character ligatures.
They evaluated 15 different models, including:
Unified multimodal models that combine vision and language.
API-based closed-source models.
Open-source API models.
Performance was measured using:
Pass@1: Success rate in a single attempt.
Pass@K: Success rate across multiple attempts.
They also analyzed model failures using Grad-CAM, a technique that visualizes which parts of an image models focus on when making predictions. Additionally, they experimented with:
Supervised fine-tuning (SFT): Updating different parts of the models’ vision and language components to improve performance.
In-context learning: Providing example images within the input to see if it helps models learn better.
What did they find?
Most models performed poorly on the TET benchmark:
All models achieved zero success rates on Pass@1 across all four tasks, indicating a failure to correctly perceive and interpret images in a single attempt.
Some incremental improvements were seen in Pass@K metrics, but these were minimal.
Grad-CAM visualizations showed that models often failed to focus on the relevant regions of images, highlighting a lack of human-like visual attention.
Fine-tuning the vision tower of the Qwen2.5-7B-VL model significantly improved its performance, whereas updating only the language backbone did not help.
Providing in-context examples did not lead to performance gains.
Why does this matter?
This study exposes a critical gap in the capabilities of current Multimodal Large Language Models: their inability to perceive and interpret visual information as humans do. This limitation restricts their usefulness in real-world applications that require genuine visual understanding, such as robotics, autonomous vehicles, and assistive technologies. The Turing Eye Test provides a valuable tool for researchers to evaluate and improve the perceptual skills of future models. The findings suggest that architectural innovations, especially targeting the vision tower component of MLLMs, are necessary to bridge the perception gap and enable models to see and understand the world more like humans.
Key Points
Most MLLMs fail to correctly interpret challenging visual tasks, even with multiple attempts.
Fine-tuning the vision component improves perception; updating only language parts does not.
Model attention visualizations reveal a lack of focus on relevant image regions.
The Turing Eye Test offers a new benchmark to evaluate visual perception in multimodal models.
A Versatile Pathology Co-pilot via Reasoning Enhanced Multimodal Large Language Model
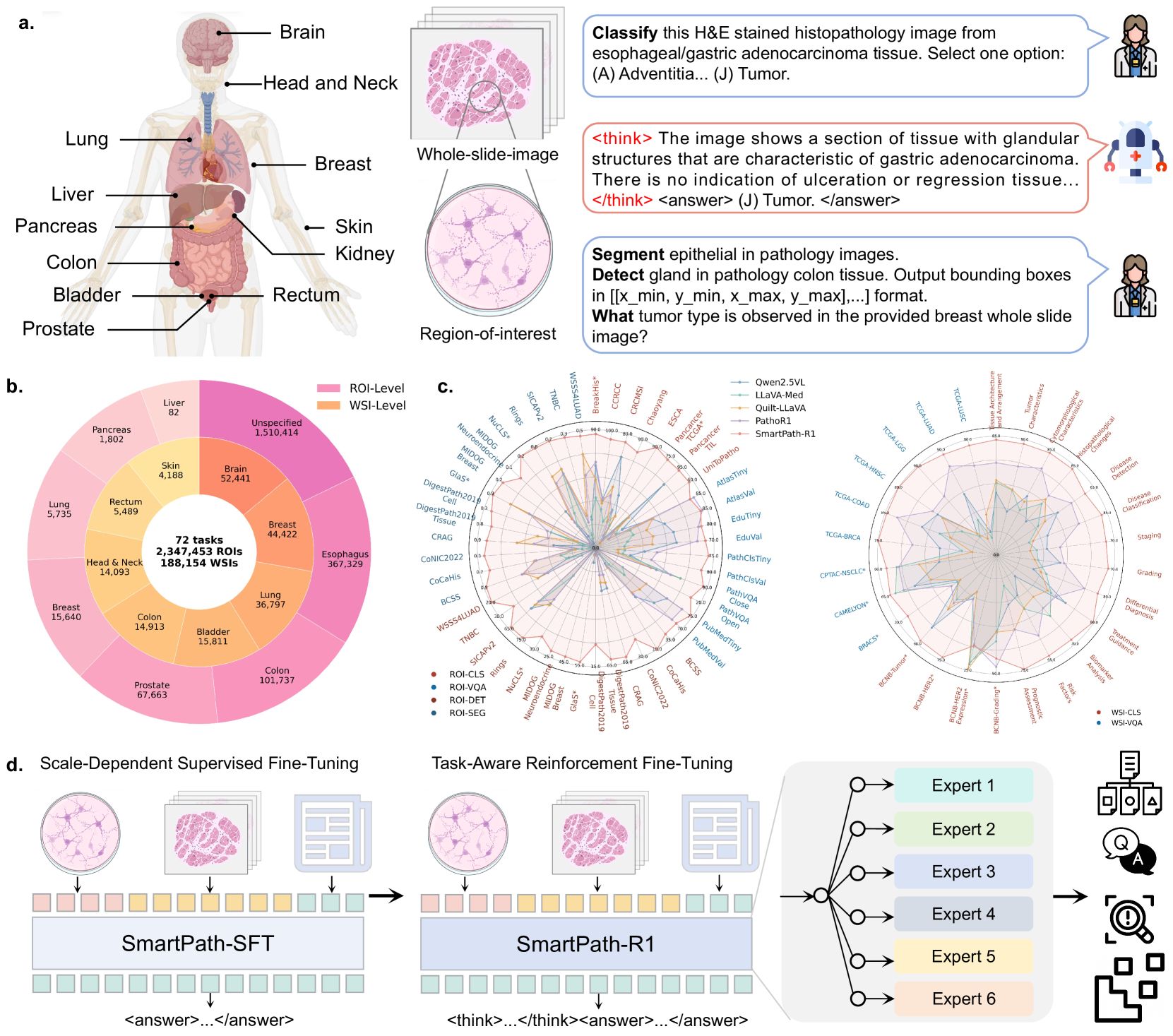
Image from arXiv paper.
What’s the research question?
How can a multimodal large language model (MLLM) be designed to improve reasoning and versatility in computational pathology tasks?
What did the authors do?
The authors developed SmartPath-R1, a novel MLLM tailored for pathology by integrating multiple advanced components:
Architecture: Built upon the Qwen2.5-VL model, combining a pre-trained Large Language Model (LLM), a Vision Encoder, and an MLP-based Vision-Language Merger.
Vision Encoder: Redesigned Vision Transformer (ViT) with 2D-RoPE and window attention for native resolution processing and faster computation.
Input Processing: Resized pathology images to multiples of 28, split into patches, and processed them efficiently.
Fusion Module: Used an MLP-based merger that spatially grouped adjacent patches, concatenated features, and projected them into a lower-dimensional space aligned with text embeddings for multimodal integration.
Task Adaptation: Employed LoRA (Low-Rank Adaptation) for efficient, task-specific fine-tuning with fewer parameters.
Dynamic Routing: Implemented a Mixture-of-Experts (MoE) approach with multiple LoRA modules for different task groups, selecting the best during inference.
Scale-aware Fine-tuning: Adjusted image resolution and token count based on task scale—ROI-level tasks used lower resolution, while Whole Slide Image (WSI)-level tasks used higher resolution.
Training: Minimized cross-entropy loss on a large curated dataset (>2.3 million samples) covering classification, detection, segmentation, and visual question answering (VQA) at both ROI and WSI levels.
Reinforcement Fine-tuning: Introduced task-specific reward functions mimicking pathologist reasoning to guide evidence gathering and improve decision policies.
What did they find?
SmartPath-R1 demonstrated remarkable performance across 72 diverse pathology tasks:
Outperformed five open-source baselines, including Qwen2.5-VL and specialized pathology models.
Achieved an average accuracy of 80.6% on ROI-level classification, 43.0% on detection, 50.0% on segmentation, and 68.3% on VQA.
Excelled in WSI-level tasks with 75.0% accuracy in classification and 69.5% in VQA.
Significantly surpassed the second-best model with 38.3% higher accuracy on ROI classification.
Generated interpretable stepwise reasoning chains and adapted effectively to diverse tasks and scales.
Limitations include the complexity of training and potential challenges in real-time deployment due to model size and inference speed.
Why does this matter?
SmartPath-R1 marks a significant advance in computational pathology by unifying reasoning and multiscale analysis within a single, versatile AI model. Its ability to handle a wide range of diagnostic tasks—such as identifying cancer subtypes, detecting lesions, segmenting tissue structures, and answering complex visual questions—mirrors the reasoning process of expert pathologists. This enhances clinical trust and interpretability, crucial for real-world adoption.
Moreover, the innovative design principles—like task-aware reinforcement fine-tuning, efficient multimodal fusion, and scale-dependent adaptation—can inform future AI systems in medicine and other fields requiring complex reasoning over multimodal data. By bridging vision and language with advanced reasoning capabilities, SmartPath-R1 paves the way for AI assistants that support clinicians in making faster, more accurate, and more explainable diagnoses.
Key Points
Developed SmartPath-R1, a multimodal large language model tailored for pathology with reasoning-enhanced capabilities.
Integrated a redesigned Vision Transformer, an MLP-based fusion module, and task-specific reinforcement fine-tuning.
Outperformed existing models across 72 pathology tasks, demonstrating superior accuracy and interpretability.
Advances multimodal AI by combining vision, language, and reasoning at multiple scales for clinical diagnostics.
Decoupling Knowledge and Reasoning in LLMs: An Exploration Using Cognitive Dual-System Theory
What’s the research question?
How can the contributions of knowledge retrieval and reasoning adjustment be decoupled in large language models (LLMs)?
What did the authors do?
The authors proposed a novel framework inspired by Kahneman's cognitive dual-system theory to analyze LLMs by separating their inference process into two distinct phases:
Knowledge retrieval (fast thinking): Generating answers based solely on stored knowledge without explicit reasoning adjustments.
Reasoning adjustment (slow thinking): Refining those answers by applying logical and domain-specific reasoning.
Applied this dual-system approach to 15 different LLMs across three diverse datasets (MMLU, MathQA, MedQA) covering general and specialized knowledge domains.
Prompted models to produce answers in each mode separately, then measured performance differences to quantify the individual contributions of knowledge and reasoning.
Analyzed how model size affects these contributions, including layer-wise knowledge storage and the impact of parameter scaling.
What did they find?
The study revealed several key insights:
Small LLMs tend to overthink: They generate more reasoning adjustments than correct answers, leading to negative reasoning gains and indicating inefficient use of reasoning capabilities.
Larger models improve both knowledge retrieval and reasoning adjustment: They produce more accurate answers and apply reasoning more prudently, resulting in positive reasoning gains.
Knowledge resides mainly in lower network layers: Early layers capture factual information, while higher layers are more involved in reasoning processes.
Domain-specific effects: Reasoning adjustment enhances performance in reasoning-intensive domains but can sometimes impair knowledge-intensive tasks if overapplied.
Parameter scaling benefits both components: Increasing model size improves knowledge retrieval and reasoning adjustment, with knowledge improvements being more pronounced than reasoning gains.
Why does this matter?
This work provides a new lens to understand how large language models process information by disentangling the roles of stored knowledge and reasoning. By explicitly separating these components, researchers can better diagnose model strengths and weaknesses, leading to more interpretable and robust AI systems. The findings highlight the importance of architectural design choices—such as layer-wise knowledge storage and reasoning strategies—and suggest that targeted improvements in either component can enhance overall model performance. This dual-system framework opens avenues for developing more efficient, domain-adaptive, and reasoning-capable LLMs, with potential applications in education, healthcare, and complex decision-making tasks where nuanced understanding and logical inference are critical.
Key Points
Introduces a dual-system framework to decouple knowledge retrieval and reasoning adjustment in LLMs.
Shows larger models better balance knowledge and reasoning, with knowledge stored mainly in lower layers.
Identifies overthinking in small models and domain-specific effects of reasoning adjustments.
Highlights the impact of model size and architecture on inference contributions.
SKA-Bench: A Fine-Grained Benchmark for Evaluating Structured Knowledge Understanding of LLMs
What’s the research question?
How effectively do large language models (LLMs) understand and reason over structured knowledge presented in various formats such as knowledge graphs, tables, and combined text-knowledge units?
What did the authors do?
The authors developed SKA-Bench, a comprehensive benchmark designed to evaluate LLMs’ ability to handle structured knowledge. Their approach included:
Data Collection: Assembling 921 question-answer pairs across four data types: Knowledge Graphs (KG), Tables, KG+Text, and Table+Text. They sourced data from existing datasets like WebQSP, CWQ, WTQ, TableBench, STaRK, and HybridQA.
Knowledge Unit Annotation: Three experts iteratively annotated the minimal set of positive knowledge units needed to answer each question, achieving over 95% agreement.
Noisy Knowledge Units Generation: Creating challenging test cases by introducing noisy (irrelevant or misleading) knowledge units using LLMs, then manually verifying their safety to prevent unfair advantages.
Testbed Construction: Designing four evaluation scenarios to test LLMs’ robustness to noise, insensitivity to knowledge order, ability to integrate multiple knowledge sources, and capacity to reject irrelevant information.
What did they find?
The evaluation of eight LLMs, including the advanced DeepSeek-R1, revealed several key insights:
Performance Challenges: All models struggled with understanding structured knowledge, especially when noise was added or the order of knowledge units was changed.
Robustness Variability: DeepSeek-R1 showed the best overall robustness across different test scenarios, but even it was affected by noise and reordering.
Hallucination and Noise Sensitivity: Models like GPT-4o exhibited significant hallucination issues and were more sensitive to noisy inputs, leading to incorrect answers.
Limitations: Current LLMs have difficulty reliably integrating and reasoning over complex structured knowledge, highlighting areas for improvement.
Why does this matter?
Understanding how well LLMs grasp structured knowledge is crucial for advancing AI systems that rely on accurate reasoning over diverse data formats. This benchmark provides a fine-grained, challenging evaluation framework that exposes the weaknesses of existing models, guiding future research to develop more robust, noise-resistant, and reasoning-capable LLMs. Improvements in this area could enhance applications like question answering, knowledge-based reasoning, and multimodal AI systems that need to unify language, vision, and structured data for real-world tasks.
Key Points
Introduces SKA-Bench, a benchmark for structured knowledge understanding in LLMs across KG, tables, and combined formats.
Highlights significant challenges in noise robustness, order sensitivity, and knowledge integration for current LLMs.
Provides a valuable tool for measuring and improving LLM reasoning over complex, structured data.
Guides future AI development towards more reliable and interpretable multimodal and knowledge-intensive models.
AQuilt: Weaving Logic and Self-Inspection into Low-Cost, High-Relevance Data Synthesis for Specialist LLMs
What’s the research question?
How can logic and self-inspection be integrated into data synthesis to improve the performance and relevance of specialized large language models?
What did the authors do?
The authors introduced AQuilt, a novel framework for generating high-quality, domain-specific training data for large language models (LLMs) by:
Constructing instruction-tuning datasets from unlabeled data using a combination of Answer, Question, Unlabeled data, Inspection, Logic, and Task type components.
Training a smaller data synthesis model on a bilingual dataset of 703,000 examples generated via DeepSeek-V3.
Incorporating explicit logical reasoning by associating task types with unlabeled data and generating question-answer pairs with logical steps using a commercial LLM.
Applying relevance-aware filtering based on inspection scores to select high-relevance, domain-specific examples.
Using a loss function that maximizes the likelihood of generating correct answer-question-logical reasoning triplets.
Supporting cross-task generalization through flexible task type definitions and evaluating on downstream tasks like extractive QA, natural language inference, and text summarization.
What did they find?
The AQuilt framework demonstrated significant improvements:
Achieved an average score of 46.18 across multiple downstream tasks, outperforming baseline models.
Requiring only 17% of the production cost of DeepSeek-V3 while maintaining comparable performance.
Ablation studies showed that removing logic or self-inspection components caused performance drops of 1.25 and 1.12 points, respectively, highlighting their importance.
Relevance analysis revealed that AQuilt’s generated data was more concentrated and less noisy than DeepSeek-V3’s, with higher Silhouette scores indicating better domain relevance.
Why does this matter?
AQuilt advances the field of data synthesis for specialized LLMs by demonstrating that integrating logic and self-inspection into data generation enhances both reasoning capabilities and relevance to target domains. Its low-cost approach makes it accessible for developing high-quality, domain-specific models in resource-constrained settings. Additionally, its support for cross-task generalization and bilingual data broadens its applicability across diverse languages and domains, enabling more effective and efficient customization of LLMs for real-world applications.
Key Points
Integrates logic and self-inspection into data synthesis to improve reasoning and relevance.
Achieves high performance with significantly lower cost compared to previous methods.
Supports cross-task generalization and bilingual data generation.
Enhances domain-specific LLM training by filtering for high-relevance examples.
Revisiting LLM Reasoning via Information Bottleneck
What’s the research question?
How can the reasoning capabilities of large language models (LLMs) be improved using an information-theoretic approach grounded in the information bottleneck (IB) principle?
What did the authors do?
The authors proposed a novel framework called IB-aware reasoning optimization (IBRO) that enhances LLM reasoning by balancing informativeness and generalization:
Introduced an IB-aware regularization that encourages reasoning trajectories to be both highly informative about the correct answer and robust across different prompts.
Maximized the mutual information between the reasoning process and the final answer while minimizing the mutual information between the reasoning process and the prompt.
Derived a practical token-level surrogate objective that approximates the intractable mutual information terms, using token advantages available during reinforcement learning (RL) training.
Integrated this IB regularization into existing RL algorithms like PPO and DAPO with minimal code changes (just one line).
What did they find?
The IBRO framework led to consistent improvements in reasoning benchmarks:
On mathematical reasoning datasets (AMC23, AIME24/25), pass rates increased from 31.5% to 33.7% with PPO and from 40.6% to 42.7% with DAPO.
Analysis showed that IB regularization maintained a balanced entropy profile, avoiding issues like entropy collapse or explosion seen with naive entropy regularization.
Preserved response length, ensuring the model's reasoning steps remained comprehensive.
Limitations include the need for careful tuning of the regularization strength and uncertainty about scalability to larger models.
Why does this matter?
This work provides a theoretically grounded, practical approach to improving LLM reasoning by leveraging the IB principle:
The token-level surrogate objective and easy-to-implement regularization make it accessible for integration into existing training pipelines.
Enhanced reasoning capabilities can lead to more reliable, trustworthy AI systems in critical applications like education, scientific research, and decision support.
The information-theoretic perspective opens new avenues for principled model improvement and alignment with human values.
Industry adoption is facilitated by minimal computational overhead and simple code modifications.
Key Points
Introduces IB-aware regularization to improve LLM reasoning by balancing informativeness and generalization.
Derives a token-level surrogate objective based on mutual information and token advantages.
Integrates seamlessly into RL training algorithms with minimal code changes.
Demonstrates empirical gains on mathematical reasoning benchmarks.
ThinkAct: Vision-Language-Action Reasoning via Reinforced Visual Latent Planning

Image from arXiv paper.
What’s the research question?
How can a dual-system framework improve embodied reasoning and long-horizon planning in vision-language-action (VLA) tasks?
What did the authors do?
The authors developed ThinkAct, a novel AI system with a dual-system architecture designed for embodied agents that need to understand and act in complex environments by integrating vision, language, and actions:
High-level reasoning module: A multimodal large language model (MLLM) generates visual plan latents based on visual inputs and instructions, capturing spatial-temporal planning intent.
Action execution module: A Transformer-based diffusion policy predicts executable actions conditioned on these visual plan latents.
Reinforcement learning with visual feedback: The system uses rewards based on goal completion and trajectory matching to train the MLLM to produce effective visual plans.
Training stages: Combines supervised fine-tuning, reinforcement learning, and imitation learning on action demonstrations to enhance robustness and adaptability.
Asynchronous operation: The reasoning and control modules operate asynchronously, allowing deliberate planning and reactive control to work together.
What did they find?
ThinkAct demonstrated significant improvements over previous methods:
Achieved a 71.5% success rate on the SimplerEnv benchmark, outperforming prior approaches by 15.5%.
Reached an 84.4% success rate on LIBERO, surpassing DiT-Policy and CoT-VLA.
Excelled in embodied reasoning tasks, outperforming baselines by 2.5 BLEU points on RoboVQA and 4.1 BLEU points on OpenEQA.
Exhibited strong few-shot adaptation, long-horizon planning, and self-correction abilities, such as replanning after failures like dropping objects.
Ablation studies confirmed the importance of visual feedback rewards, with performance drops when removing trajectory or goal rewards.
Limitations include the complexity of training and potential challenges in scaling to more diverse or real-world environments.
Why does this matter?
ThinkAct advances the state of embodied AI by effectively combining high-level reasoning with low-level action control through visual latent planning. Its ability to perform long-horizon planning, adapt quickly to new situations, and recover from failures addresses key challenges in robotics, augmented reality, and other embodied AI applications. By demonstrating robust and scalable integration of vision, language, and action, ThinkAct paves the way for more intelligent, adaptable agents that can operate seamlessly in complex, dynamic environments—bringing us closer to truly autonomous embodied systems capable of understanding and manipulating the world with human-like flexibility.
Key Points
Introduces a dual-system architecture combining a multimodal language model and a diffusion-based action model.
Uses reinforced visual latent planning to enable long-horizon, goal-directed reasoning.
Achieves significant performance gains on multiple embodied reasoning benchmarks.
Demonstrates strong adaptability, self-correction, and re-planning capabilities.
Can One Domain Help Others? A Data-Centric Study on Multi-Domain Reasoning via Reinforcement Learning
What’s the research question?
How does training large language models (LLMs) across multiple reasoning domains affect their ability to generalize and perform on diverse tasks?
What did the authors do?
The authors conducted a comprehensive study using the Qwen-2.5-7B model family to explore how multi-domain training influences reasoning capabilities. Their approach included:
Training models on three distinct reasoning domains: mathematical problem-solving, code generation, and logical puzzles.
Using curated datasets for each domain: DeepScaleR and CountDown for math, CodeR1-12k for coding, and Knights-and-Knaves plus Logic Puzzle Baron for puzzles.
Applying the Group Relative Policy Optimization (GRPO) algorithm combined with supervised fine-tuning (SFT) and reinforcement learning (RL) with verifiable rewards tailored to each task.
Ensuring consistency by training and testing models with the same instruction templates (R1-template).
Evaluating models both within each domain (in-domain) and across different domains (out-of-domain), including benchmarks like MATH500, HumanEval, ZebraLogicBench, and CountDown.
Investigating the effects of curriculum learning strategies, reward design variations, and training language choices on model performance.
What did they find?
The study revealed nuanced insights into multi-domain training effects:
Single-domain training improved performance within that domain but often hurt out-of-domain generalization, with models excelling on math but struggling on unrelated tasks.
Combining domains generally led to mutual benefits, such as improved puzzle-solving and math reasoning, but sometimes caused conflicts, notably reducing coding performance.
Instruction tuning (SFT) models consistently outperformed base models, highlighting the importance of instruction-based training.
Curriculum learning and reward design strategies, including staged training and adaptive rewards, enhanced the models’ ability to generalize across tasks.
Limitations include potential domain conflicts and the challenge of balancing training objectives to optimize overall versatility.
Why does this matter?
This research advances our understanding of how multi-domain training shapes the reasoning abilities of large language models. By demonstrating that carefully curated multi-domain curricula and reward schemes can improve both in-domain and out-of-domain performance, it provides practical guidance for developing more versatile and robust AI systems. Such models are better equipped to handle real-world applications where diverse reasoning skills are required, from mathematical problem-solving and coding to logical deduction. This work helps bridge the gap between specialized expertise and generalist AI, paving the way for models that can adaptively learn and reason across a wide array of tasks.
Key Points
Multi-domain training can enhance reasoning capabilities but requires careful balancing to avoid domain conflicts.
Instruction tuning significantly improves model performance over base training approaches.
Curriculum learning and adaptive reward design are effective strategies for improving out-of-domain generalization.
The study offers practical guidelines for designing multi-domain reasoning curricula in large language models.