- TensorTeach's Newsletter
- Posts
- Universal Multimodal Retrieval, Merge-of-Thought Distillation, Long-Horizon LLM Execution, LLMs as RL Tutors, Holistic Audio-LLM Evaluation
Universal Multimodal Retrieval, Merge-of-Thought Distillation, Long-Horizon LLM Execution, LLMs as RL Tutors, Holistic Audio-LLM Evaluation
TensorTeach AI
September 12, 2025
Recurrence Meets Transformers for Universal Multimodal Retrieval
What’s the research question?
How can we develop a unified multimodal retrieval model that supports diverse query and document configurations, including missing modalities?
What did the authors do?
The authors introduced ReT-2, a novel model designed to improve multimodal retrieval by combining recurrence and transformer architectures:
Developed a shared encoder architecture that processes both visual and textual features using a recurrent cell.
Integrated features from visual and textual backbones at selected layers through a recurrent cell equipped with gating mechanisms inspired by LSTMs, enabling dynamic fusion of information across layers and modalities.
Used a single token embedding for both queries and documents to simplify the model and accelerate inference.
Trained the model with an InfoNCE loss to maximize similarity between relevant query-document pairs and minimize it for irrelevant pairs.
What did they find?
ReT-2 achieved state-of-the-art performance on key benchmarks:
Outperformed previous methods on the M2KR and M-BEIR benchmarks across various retrieval tasks, including text-to-image, image-to-text, and multimodal-to-multimodal retrieval.
Demonstrated strong generalization capabilities, effectively handling missing modalities and diverse query/document configurations.
Showed improved efficiency with faster inference times and lower memory usage compared to prior approaches.
Limitations include potential complexity in tuning gating mechanisms and the need for extensive training data to fully leverage the recurrent fusion.
Why does this matter?
ReT-2 advances multimodal retrieval by providing a unified, efficient framework that can handle the complexity of real-world multimodal data. Its ability to fuse features dynamically across layers and modalities, while robust to missing information, makes it highly applicable to practical applications such as:
Search engines that need to retrieve images, text, or combined content based on diverse queries.
Multimedia content organization and recommendation systems.
Assistive technologies that interpret and relate visual and textual information.
By bridging recurrence and transformers, ReT-2 opens new avenues for more flexible and powerful multimodal AI systems.
Key Points
Unified multimodal retrieval model combining recurrence and transformers with gating mechanisms.
Handles diverse query and document configurations, including missing modalities.
Achieves state-of-the-art results on multiple benchmarks with improved efficiency.
Supports real-world applications requiring flexible multimodal understanding.
Merge-of-Thought Distillation: Unifying Reasoning Styles in Large Language Models
What’s the research question?
Can multiple heterogeneous teacher models with different reasoning styles be integrated into a single student model to enhance reasoning capabilities in large language models?
What did the authors do?
The authors introduced Merge-of-Thought Distillation (MoT), a novel approach to combine diverse reasoning styles from multiple teacher models into one unified student model. Their methodology involved:
Starting with a base language model as the student.
Iteratively refining the student through multiple rounds of training.
In each round, creating K branches, each fine-tuned on a dataset generated by a specific teacher model.
Datasets contained reasoning problems, teacher rationales, and correct answers, filtered to include only correct teacher outputs.
Each branch learned to produce the same rationale as its teacher, internalizing different reasoning styles.
After fine-tuning, merging the K branches by averaging their parameters to form a new initialization for the next round.
Repeating this process for T rounds to unify diverse reasoning styles into a consensus.
What did they find?
The MoT approach achieved impressive results:
Outperformed strong baseline models on competition math benchmarks using only about 200 high-quality Chain-of-Thought (CoT) samples.
Surpassed models like DEEPSEEK-R1, QWEN3-30B, and OPENAI-O1.
Mitigated catastrophic forgetting by preserving diverse reasoning styles across rounds.
Improved general reasoning capabilities and robustness to distribution shifts.
Showed strong gains over single-teacher and naive multi-teacher distillation methods in ablation studies.
Why does this matter?
This work demonstrates that unifying multiple reasoning styles from diverse teacher models can create more robust, flexible, and generalizable large language models. It challenges the common assumption that a single "best" teacher suffices, highlighting the value of integrating multiple perspectives to improve complex reasoning tasks. The MoT approach offers a scalable way to enhance reasoning abilities in LLMs, with potential applications in education, AI assistants, and problem-solving domains where diverse reasoning approaches are beneficial.
Key Points
Merge-of-Thought Distillation (MoT) combines multiple reasoning styles into one model.
Iterative fine-tuning and weight-space merging create a unified student model.
Achieves strong performance on math benchmarks with limited high-quality data.
Outperforms single-teacher and naive multi-teacher distillation methods.
The Illusion of Diminishing Returns: Measuring Long Horizon Execution in LLMs
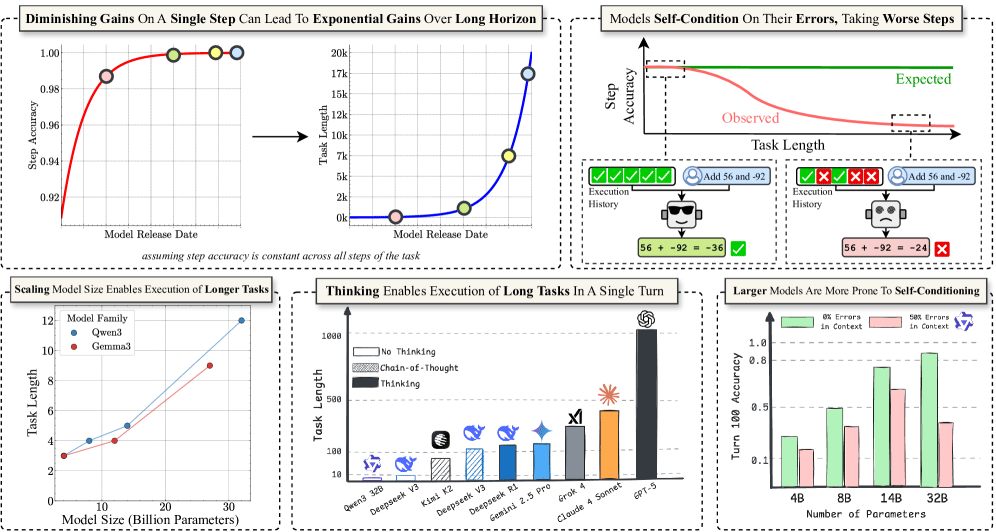
Image from arXiv paper.
What’s the research question?
How do large language models (LLMs) perform on tasks that require sustained, multi-step execution over long sequences, and what factors influence their ability to handle such long-horizon tasks?
What did the authors do?
The authors developed a controlled experimental framework to evaluate long-horizon execution in LLMs, focusing on the following key aspects:
Task Design: Introduced a simple retrieve-then-compose task where models are given explicit knowledge and plans, removing reasoning complexity. The task involves maintaining a running sum of values associated with keys, requiring retrieval and composition at each turn.
Evaluation Metrics: Measured turn accuracy (correctness per step), task accuracy (correct execution of entire sequences), and horizon length (longest sequence successfully completed).
Model Variants: Tested multiple models from the Qwen3 and Gemma3 families, ranging from 4 billion to 32 billion parameters.
Experimental Variables: Varied the number of turns, turn complexity (number of steps per turn), and manipulated chat history to introduce errors, analyzing their effects on performance.
Benchmarking: Compared frontier models like GPT-5, enabling explicit reasoning (thinking) to assess improvements in long-horizon execution.
What did they find?
The study revealed several important insights:
Scaling Benefits: Larger models maintained higher task accuracy over more turns, with the horizon length growing exponentially once turn accuracy exceeded 70%.
Degradation Factors: Turn accuracy degraded over time due to long-context issues and a self-conditioning effect, where models became more prone to errors after observing their own mistakes. This effect persisted even in large models and was not mitigated by increasing model size.
Role of Explicit Reasoning: Enabling models like GPT-5 to perform explicit reasoning (thinking) during execution eliminated the self-conditioning problem and enabled the model to handle over 1,000 steps in a single turn.
Why does this matter?
This work challenges the common assumption that diminishing returns in single-turn accuracy limit long-term capabilities of LLMs. It demonstrates that:
Long-horizon performance can be dramatically improved by scaling model size and test-time compute, highlighting the importance of evaluating models in long-sequence settings rather than just single-turn accuracy.
Self-conditioning effects pose a significant challenge to sustained long-horizon execution, suggesting the need for methods that incorporate explicit reasoning or self-correction.
The findings have broad implications for developing more reliable, scalable AI agents capable of complex, multi-step tasks in real-world applications such as autonomous agents, planning, and multi-modal reasoning.
Key Points
Large language models' ability to execute long sequences improves exponentially with size once high turn accuracy is achieved.
Self-conditioning errors cause degradation over time, even in large models, but can be fixed with explicit reasoning.
Evaluating long-horizon tasks reveals capabilities hidden by single-turn accuracy metrics.
Scaling and reasoning enhancements are crucial for building more capable AI agents.
Accelerating Reinforcement Learning Algorithms Convergence using Pre-trained Large Language Models as Tutors With Advice Reusing
What’s the research question?
Can pre-trained Large Language Models (LLMs) serve as effective tutors to speed up the convergence of reinforcement learning (RL) algorithms without sacrificing optimality?
What did the authors do?
The authors explored a novel student-teacher framework where:
RL algorithms (DQN, PPO, A2C) act as students learning to solve tasks in environments like Blackjack, Snake, and Connect Four.
Pre-trained LLMs (Llama3.1, Vicuna, DeepSeek-R1) serve as tutors providing advice to guide RL agents.
Advice from LLMs is probabilistically consulted by RL agents, with the likelihood decreasing over time to encourage exploration.
Implemented advice reuse by storing guidance for states and reusing it based on a budget and a decay-based probability, aiming to leverage past guidance efficiently.
Modified RL algorithms to incorporate LLM advice, replacing traditional exploration strategies.
Measured convergence speed using a normalized metric over training steps and evaluated time savings from advice reuse.
What did they find?
Key results include:
LLM tutoring improved RL convergence speed across 54 different configurations, achieving faster learning without losing optimal performance.
DeepSeek-R1 consistently outperformed other LLMs in both convergence speed and time savings, indicating the importance of LLM choice.
Advice reuse further accelerated convergence but introduced some instability, highlighting a trade-off between efficiency and stability.
The effectiveness of LLM guidance was influenced by environment complexity and the specific RL algorithm used, suggesting that tuning is necessary for different settings.
Limitations noted include potential instability from advice reuse and sensitivity to environment and algorithm choices.
Why does this matter?
This work demonstrates a promising new way to leverage the knowledge embedded in large pre-trained LLMs to enhance reinforcement learning. By acting as intelligent tutors, LLMs can significantly reduce the number of training steps needed for RL agents to learn effective policies, which is crucial in environments where data collection is costly or slow. The advice reuse mechanism offers a practical approach to maximize the benefit of past guidance, although it requires careful management to avoid instability. These insights open avenues for integrating LLMs and RL more deeply, potentially enabling faster and more sample-efficient learning in complex, real-world tasks such as robotics, game playing, and decision-making systems.
Key Points
Pre-trained LLMs can serve as tutors to accelerate RL convergence without sacrificing optimality.
Advice reuse improves efficiency but can cause instability, requiring careful tuning.
DeepSeek-R1 outperformed other LLMs in both convergence speed and time savings.
Environment complexity and RL algorithm choice affect the effectiveness of LLM guidance.
AU-Harness: An Open-Source Toolkit for Holistic Evaluation of Audio-LLMs

Image from arXiv paper.
What’s the research question?
How can we develop an efficient, comprehensive, and customizable evaluation framework for Large Audio Language Models (LALMs)?
What did the authors do?
The authors introduced AU-Harness, a modular and scalable evaluation toolkit designed specifically for LALMs, which handle both language and audio data. Key features include:
Config Module: Allows hierarchical task setup and standardized prompts to customize evaluation scenarios.
Request Controller: Manages token-based requests across multiple models and datasets, optimizing resource use with adaptive retries.
Concurrent Engines: Execute multiple evaluation tasks in parallel, supporting multi-model comparisons and dataset sharding for high throughput.
Task Coverage: Supports six broad categories: Speech Recognition, Paralinguistics, Spoken Language Understanding, Audio Understanding, Spoken Language Reasoning, and Safety & Security.
Novel Tasks: Introduces LLM-Adaptive Diarization (integrating speaker info into transcripts) and Spoken Language Reasoning (audio-conditioned cognitive tasks).
Implementation: Built in Python with integrations for vLLM and Hugging Face Transformers.
What did they find?
AU-Harness demonstrated significant improvements over existing evaluation tools:
Achieved up to 127% speedup through optimized batching and parallel execution.
Processed 95.19% more samples per second and reduced real-time factor (RTF) by 59%, enabling faster large-scale benchmarking.
Revealed important gaps in LALMs’ temporal understanding and spoken language reasoning abilities. For example, GPT-4o-mini scored 38.06/100 on Speech-IFEval (audio instruction following) but 45.20/100 on the text version, indicating a 7.14-point gap.
Enabled detailed evaluation of speaker diarization by integrating speaker info into transcripts and measuring Word-diarization Error Rate (WDER).
Why does this matter?
As audio-language models become increasingly important for applications like voice assistants, multimedia understanding, and accessibility, having a comprehensive and efficient evaluation framework is crucial. AU-Harness provides researchers and developers with a powerful tool to accurately assess LALMs’ strengths and weaknesses across diverse audio and language tasks. Its scalability and extensibility accelerate progress by enabling large-scale benchmarking and detailed analysis, ultimately helping to build more capable, reliable, and fair audio-language AI systems.
Key Points
AU-Harness is an open-source toolkit for holistic evaluation of Large Audio Language Models (LALMs).
Features modular design with configurable prompts, request management, and parallel task execution.
Supports six broad audio-language task categories, including novel ones like LLM-Adaptive Diarization and Spoken Language Reasoning.
Achieves significant speedups and reveals critical gaps in LALMs’ temporal and reasoning abilities.