- TensorTeach's Newsletter
- Posts
- Reinforcement Trained Reasoners, Teacher Hints, and Adaptive Thinking: Three Paths to Smarter LLMs
Reinforcement Trained Reasoners, Teacher Hints, and Adaptive Thinking: Three Paths to Smarter LLMs
TensorTeach AI
July 04, 2025
MOTIF: Modular Thinking via Reinforcement Fine-tuning in LLMs
What’s the research question?
Can reinforcement learning be used to enable large language models (LLMs) to think modularly over multiple rounds of inference without relying on explicit process supervision?
What did the authors do?
The authors introduced MOTIF, a novel training approach for LLMs focused on improving their ability to perform multi-round, modular reasoning by:
Designing a multi-round inference architecture where the model generates thinking tokens (partial reasoning steps) and answer tokens (current answers) in each round.
Training the model using reinforcement learning with a group relative policy optimization (GRPO) algorithm that evaluates the final answer correctness after multiple reasoning rounds, rather than supervising each reasoning step.
Employing an outcome-based reward function that rewards the model based on the probability of obtaining the correct final answer, encouraging effective modular reasoning.
Fine-tuning the model on the GSM8K dataset using parameter-efficient low-rank adaptation (LoRA), updating only a small subset of parameters to improve training efficiency.
Evaluating the trained model on MATH500 and AIME2024 benchmarks, measuring pass@1 accuracy (correct answer on the first attempt).
What did they find?
The MOTIF approach yielded promising results:
Achieved a pass@1 accuracy of 48.6% on MATH500 and 6.67% on AIME2024, outperforming vanilla GRPO-trained models by 3.8% and 3.3%, respectively.
Demonstrated high sample efficiency by achieving these gains using only 15% of the training samples compared to standard GRPO training.
Showed a steady increase in expected reward during training and a slight decrease in response length, indicating the model learned to generate more effective modular reasoning responses.
Limitations include relatively modest absolute accuracy on AIME2024 and the need for further scaling and testing on diverse reasoning tasks.
Why does this matter?
MOTIF offers a powerful new way to train LLMs for complex, multi-step reasoning without requiring detailed supervision of each reasoning process. Its outcome-based reward and modular inference architecture enable models to better break down problems into reasoning steps and improve answer accuracy. The approach’s high sample efficiency makes it practical for training large models with limited data. This advancement could lead to more capable AI systems that reason more like humans—flexibly combining knowledge and logic over multiple turns—benefiting applications in education, scientific problem-solving, and complex decision-making.
Key Points
Introduces MOTIF, a reinforcement learning-based method for modular reasoning in LLMs.
Uses a multi-round inference architecture with thinking and answer tokens.
Employs outcome-based rewards to guide learning without process supervision.
Achieves significant performance gains with high sample efficiency on reasoning benchmarks.
Multi-level Stepwise Hints Enhance Reinforcement Learning to Reason
What’s the research question?
Can providing multi-level stepwise hints from stronger models improve the efficiency and reasoning abilities of reinforcement learning (RL) models?
What did the authors do?
The authors proposed a novel method to incorporate hints into RL training to boost reasoning capabilities:
Generated reasoning chains from powerful, pretrained models acting as "teachers".
Partitioned these reasoning chains into multiple steps using an adaptive method that estimates the likelihood of concluding the chain at each token.
Constructed multi-level hints by concatenating initial reasoning steps, providing progressively more guidance.
Trained RL models to generate completions from each hint level and from scratch, using the VeRL framework with a batch size of 128 and a learning rate of 1e-6.
Evaluated performance on six math datasets and out-of-domain benchmarks, comparing against baseline RL methods.
What did they find?
The approach yielded significant improvements:
Achieved an average accuracy of 29.33% on in-domain math tasks, outperforming the vanilla baseline by 4.66%.
Attained an average pass@5 accuracy of 82.80% on out-of-domain tasks, surpassing the baseline by 25.00%.
Demonstrated faster convergence and higher reward scores during training.
Produced more diverse policies and longer, more detailed responses.
Limitations include reliance on strong teacher models for generating hints and potential challenges in scaling adaptive partitioning to very long reasoning chains.
Why does this matter?
This work introduces a powerful new way to enhance RL-based reasoning by integrating external hints at multiple levels of detail. By guiding models with structured reasoning steps from stronger teachers, it improves learning efficiency and reasoning depth, which is crucial for complex tasks like mathematics, coding, and scientific discovery. The approach could lead to more capable AI agents that reason more like humans, with applications spanning education, automated problem-solving, and intelligent assistants.
Key Points
Multi-level stepwise hints from stronger models boost RL reasoning and learning speed.
Adaptive partitioning estimates when to conclude reasoning steps, creating effective hints.
Significant improvements on math benchmarks, including out-of-domain generalization.
Potential to advance AI reasoning in diverse applications requiring complex, multi-step thinking.
Mixture of Reasonings: Teach Large Language Models to Reason with Adaptive Strategies
What’s the research question?
Can large language models (LLMs) be trained to reason adaptively and effectively across diverse reasoning tasks without relying on external prompt engineering?
What did the authors do?
The authors introduced a novel framework called Mixture of Reasoning (MoR) that enables LLMs to learn multiple reasoning strategies internally. Their approach involves two main phases:
Thought Generation: Using GPT-4o (an advanced LLM), they generated a variety of reasoning chain templates that cover different reasoning patterns, such as logical inference, multi-step deduction, and theory of mind.
SFT Dataset Construction: These templates were paired with samples from several benchmark datasets (HotpotQA, StrategyQA, MMLU, BigTom, Trivial Creative Writing). For each sample, a subset of reasoning templates was selected, and GPT-4o identified the most beneficial template. The sample and chosen template were combined into a prompt, which was then used to generate reasoning responses. Correct responses formed a supervised fine-tuning (SFT) dataset, enabling the model to learn to select and apply reasoning strategies autonomously.
They fine-tuned LLMs on this diverse, strategy-rich dataset to teach them adaptive reasoning without external prompts.
What did they find?
The MoR-trained models demonstrated significant improvements:
Models trained with 150 reasoning chains (MoR 150) achieved 0.730 accuracy with Chain-of-Thought prompting and 0.734 with Input-Output prompting.
These scores represent 2.2% and 13.5% improvements over baseline models without MoR.
MoR models excelled in multi-step inference and strategy-oriented reasoning tasks.
Performance remained strong on larger datasets (200 samples), indicating good generalization.
Case studies showed the model effectively applied logical reasoning and theory of mind skills, demonstrating versatile reasoning capabilities.
Limitations include the reliance on GPT-4o for template generation and selection, which may introduce biases, and the need for further testing on more complex or real-world tasks.
Why does this matter?
This work advances AI reasoning by showing that embedding a diverse set of reasoning strategies directly into LLMs can significantly enhance their ability to tackle complex, multi-faceted problems. Unlike previous approaches that depended heavily on external prompt engineering, MoR trains models to autonomously select and apply reasoning strategies, improving robustness and generalizability across domains. This has broad implications for developing AI systems capable of more human-like reasoning, including applications in question answering, creative writing, and decision-making, where flexible and adaptive reasoning is crucial.
Key Points
MoR trains LLMs to reason adaptively by embedding multiple reasoning strategies.
Generated reasoning templates cover diverse patterns like logic, multi-step inference, and theory of mind.
Achieved over 13% improvement in accuracy compared to baseline models.
Models demonstrated strong generalization and versatility across reasoning tasks.
Reasoning on a Budget: A Survey of Adaptive and Controllable Test-Time Compute in LLMs
What’s the research question?
How can large language models (LLMs) optimize their reasoning efficiency through controllable and adaptive test-time compute strategies?
What did the authors do?
The paper introduces a comprehensive framework to categorize and evaluate strategies that manage computational resources during LLM inference:
Two-tiered taxonomy: Divides test-time compute (TTC) strategies into L1 (controllable) and L2 (adaptive).
L1 strategies: Fixed compute budgets per inference, allowing user constraints such as token limits or sample sizes. Includes:
Sequential prompting: Generate responses step-by-step, controlling reasoning depth.
Parallel prompting: Sample multiple solutions simultaneously, then aggregate results.
L2 strategies: Dynamically allocate compute based on input difficulty or model confidence. Includes:
MetaReasoner: Use high-level strategies to adapt reasoning efforts.
Feedback-based methods (RASC, DAST): Incorporate feedback during inference to optimize computational resource use.
Benchmarking: Evaluated various models across multiple datasets, measuring token efficiency and reasoning accuracy.
What did they find?
Key empirical insights include:
Models often overthink simple problems and underthink complex ones, revealing inefficiencies in test-time compute management.
Claude 3.7 adhered to a predefined 'thinking budget' but sometimes exceeded it, highlighting challenges in consistent budget control.
High-performing models like o1 and DeepSeek-R1 generated longer responses but achieved superior accuracy on complex tasks.
Token usage and reasoning performance varied widely among models, with some achieving significant token savings without accuracy loss, while others suffered from over- or underthinking.
Why does this matter?
Efficient reasoning is crucial for deploying large language models in real-world applications where computational resources and latency matter:
Structured framework: The L1/L2 taxonomy helps researchers and practitioners understand and design better test-time compute strategies.
Resource-aware models: Adaptive and controllable compute methods enable LLMs to balance reasoning depth and efficiency, reducing costs and improving responsiveness.
Practical impact: Insights into token efficiency and reasoning accuracy inform deployment in latency-sensitive settings like autonomous agents, virtual assistants, and real-time decision-making systems.
Future directions: The survey highlights challenges and opportunities for developing scalable, flexible LLMs that can reason effectively under resource constraints.
Key Points
Introduces a two-tiered taxonomy for test-time compute strategies: controllable (L1) and adaptive (L2).
Benchmarks various models on token efficiency and reasoning accuracy across multiple datasets.
Identifies common inefficiencies: overthinking simple problems and underthinking complex ones.
Provides practical insights for designing resource-aware LLM inference methods.
Reasoning or Not? A Comprehensive Evaluation of Reasoning LLMs for Dialogue Summarization
What’s the research question?
Can explicit step-by-step reasoning in large language models (LLMs) improve their performance on dialogue summarization tasks, or does it introduce challenges like verbosity and factual errors?
What did the authors do?
The authors conducted a systematic comparison between reasoning and non-reasoning LLMs on dialogue summarization, using multiple datasets and paradigms:
Models evaluated: Reasoning LLMs (OpenAI-o1, DeepSeek-R1, QwQ-32B) versus their non-reasoning counterparts.
Dialogue paradigms: Generic, role-oriented (CSDS), and query-oriented (QMSum) summarization.
Datasets: SAMSum, DialogSum, CSDS, and QMSum, covering diverse dialogue types and summarization goals.
Prompting: Standardized templates to ensure fair comparison.
Evaluation metrics: Traditional metrics (ROUGE, BLEU, CHRF, BERTScore, COMET, MoverScore, BARTScore) and LLM-based human-aligned metrics.
Reasoning trace analysis: For reasoning models, explicit reasoning steps were generated and evaluated for relevance, validity, coherence, utility, and depth.
Case study: In-depth analysis of how reasoning traces affected summary quality.
What did they find?
Contrary to common assumptions, reasoning LLMs did not outperform non-reasoning models:
Performance: Non-reasoning LLMs achieved higher scores across all datasets and metrics. For example, DeepSeek-V3 (non-reasoning) scored highest on ROUGE, while GPT-4o (non-reasoning) excelled on BERTScore.
Reasoning models’ shortcomings: Reasoning models like DeepSeek-R1 and QwQ-32B consistently underperformed their non-reasoning counterparts.
Task-specific results: In role-oriented dialogue summarization (CSDS), reasoning models performed worse across all metrics. Similarly, in query-oriented summarization (QMSum), reasoning models lagged behind.
Limitations: Explicit reasoning traces sometimes introduced verbosity, factual inconsistencies, and reduced relevance or coherence in summaries.
Why does this matter?
These findings challenge the prevailing belief that explicit reasoning enhances dialogue summarization. They suggest that:
Current reasoning LLMs may not be well-suited for this task and could even hinder performance.
Model development should carefully consider whether reasoning steps add value or introduce noise.
Evaluation strategies need to account for both factual accuracy and the quality of reasoning traces.
This work highlights the importance of aligning model capabilities with specific task requirements, especially in complex dialogue settings where clarity and correctness are crucial.
Broader implications include guiding future research on how to effectively integrate reasoning into language models without sacrificing summarization quality.
Key Points
Explicit reasoning in LLMs does not necessarily improve dialogue summarization; non-reasoning models often perform better.
Reasoning traces can introduce verbosity and factual errors, reducing summary quality.
The study covers diverse dialogue types and evaluation metrics, providing a comprehensive comparison.
Findings inform future model design and evaluation strategies for dialogue understanding tasks.
MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent
What’s the research question?
How can large language models (LLMs) effectively process and extrapolate from arbitrarily long input texts while maintaining performance and efficiency?
What did the authors do?
The authors introduced MemAgent, a novel architecture designed to enable LLMs to handle extremely long texts efficiently:
Segmented Processing: The model divides long inputs into manageable segments, processing each sequentially.
Fixed-Length Memory: Maintains a fixed-size memory that summarizes previous segments, preventing input length from exploding.
Memory Update via Reinforcement Learning (RL): Uses a learned overwrite strategy to update memory with each new segment, replacing old summaries with new ones based on learned policies.
Optimization with Multi-Conversation DAPO: Trains the memory update policy using Deep Advantage Policy Optimization (DAPO), treating each segment as an independent RL target to improve robustness.
Training on Synthetic Long-Context Tasks: Uses synthetic question-answering tasks with a rule-based verifier to generate rewards, ensuring the model learns effective memory updates.
Compatibility: Designed to work with existing dense attention transformer architectures without requiring architectural changes.
What did they find?
MemAgent achieved impressive results in processing long texts:
Near-Lossless Extrapolation: Extended an 8,000-token context window to handle up to 3.5 million tokens with less than 5% performance loss.
High Accuracy: Achieved over 95% accuracy on RULER benchmark tasks with context lengths up to 512,000 tokens.
Importance of RL-Trained Memory: Ablation studies showed that the RL-trained memory policy was crucial; untrained memory led to degraded performance, highlighting the benefit of learned memory updates.
Efficiency: Maintains linear time complexity, making long-context processing computationally feasible.
Why does this matter?
Handling long inputs is a major challenge for LLMs, limiting their ability to reason over extended documents, conversations, or datasets. MemAgent offers a scalable solution by combining a fixed-length, RL-trained memory with an efficient segment-based processing strategy, enabling LLMs to reason over millions of tokens without architectural overhauls. This advancement opens new possibilities for applications requiring deep understanding of lengthy texts, such as legal documents, scientific papers, or long-form conversations, pushing the boundaries of what large language models can achieve in real-world scenarios.
Key Points
MemAgent uses a fixed-length memory updated via reinforcement learning to process arbitrarily long texts efficiently.
Segments are processed sequentially, with memory summaries overwritten using a learned policy.
Achieves near-perfect extrapolation from 8K to 3.5M tokens with minimal performance loss.
Designed to be compatible with existing transformer architectures without modifications.
Thinking About Thinking: SAGE-nano’s Inverse Reasoning for Self-Aware Language Models
What’s the research question?
How can large language models be designed to introspect and explain their own reasoning processes effectively?
What did the authors do?
The authors developed SAGE-nano, a 4-billion-parameter transformer-based language model focused on inverse reasoning—the ability to explain why certain reasoning paths were chosen over others. Their approach includes:
A metacognitive architecture with three core components:
Forward Reasoning Module (FRM): Generates chain-of-thought (CoT) reasoning sequences and tracks detailed intermediate states, including hidden states and attention weights.
Inverse Analysis Layer (IAL): Reconstructs decision pathways by analyzing attention patterns and hidden states, identifying key decision points, confidence scores, alternative considerations, and rationales.
Explanation Generation Module (EGM): Synthesizes the inverse reasoning analysis into human-readable explanations, justifying each step, alternative paths, and confidence levels.
Trained the model using a meta-learning objective combining reasoning accuracy, explanation quality, and consistency.
Evaluated on diverse reasoning tasks: mathematical, logical, and commonsense reasoning, measuring both accuracy and explanation clarity.
What did they find?
Key results include:
SAGE-nano achieved 74.6% accuracy on the AQUA-RAT math reasoning dataset, outperforming many larger models.
Human evaluators preferred its explanations 92.1% of the time, citing clarity and completeness.
The Inverse Analysis Layer contributed most to performance, with a 5.2% accuracy boost when included in ablation studies.
Its introspective capabilities—confidence calibration and decision point identification—achieved 91.2% and 89.3% accuracy, respectively.
Computational overhead was manageable: 14% increase in inference time and 10% increase in memory usage.
Why does this matter?
This work demonstrates that inverse reasoning can significantly enhance both the interpretability and effectiveness of language models. By enabling models to explain their own reasoning pathways and consider alternatives, SAGE-nano advances the goal of metacognitive AI—systems that can think about their own thinking. This has broad implications for AI transparency, safety, and trustworthiness, especially in applications requiring human-AI collaboration, education, and scientific discovery. Moreover, the architecture provides a scalable blueprint for integrating inverse reasoning into larger models and multimodal systems, aligning well with your interests in multimodal AI and agents that need self-awareness and explainability.
SurgVisAgent: Multimodal Agentic Model for Versatile Surgical Visual Enhancement
What’s the research question?
Can a unified multimodal large language model (MLLM) framework improve the quality and robustness of surgical visual enhancement across a wide range of distortion types and severities?
What did the authors do?
The authors developed SurgVisAgent, an end-to-end surgical vision agent that combines multiple advanced AI components to enhance surgical images affected by various distortions. Its key features include:
Dual-pathway architecture: A Surgical Prior Model predicts probabilistic distributions over distortion categories (e.g., blur, overexposure, smoke) and severity levels, embedding domain-specific knowledge.
Visual Encoder: Processes surgical images using Base64 encoding to enable high-level analysis without redundant feature extraction.
Multimodal Large Language Model (MLLM) Agent: Integrates outputs from the prior model and visual encoder with contextual examples provided through in-context few-shot learning.
Chain-of-Thought (CoT) reasoning: Guides the agent to formulate targeted enhancement strategies by reasoning through the distortion types and severities.
Dynamic invocation of specialized enhancement models: Based on predictions, the agent selectively activates the best foundational enhancement model from a set including DiffLL (low-light), FECNet (overexposure), MIMO-UNet+ (deblurring), and DeSmoke-LAP (smoke removal).
What did they find?
SurgVisAgent demonstrated strong performance on a comprehensive surgical image benchmark:
84% accuracy in predicting distortion severity levels.
97% accuracy in identifying distortion categories.
83% accuracy in combined distortion and severity prediction.
Outperformed traditional single-task models in both enhancement quality and robustness, measured by improvements in SSIM, PSNR, and LPIPS metrics across diverse distortion scenarios.
Ablation studies confirmed that incorporating few-shot samples and domain-specific priors significantly boosted performance.
However, the study focused on simulated distortions and a specific set of enhancement models, which may limit generalization to all real-world surgical conditions.
Why does this matter?
Surgical environments demand clear, high-quality visualizations for effective decision-making. Distortions like low-light conditions, overexposure, smoke, and motion blur can impair surgeons’ perception and increase risks. SurgVisAgent’s unified multimodal approach enables real-time, context-aware enhancement tailored to complex and diverse distortions. By dynamically selecting the best enhancement strategies based on learned priors and reasoning, it offers a more intelligent and versatile tool for surgical visualization. This advancement has the potential to improve surgical accuracy, safety, and outcomes, and paves the way for more adaptive AI-powered surgical assistance systems.
Key Points
Introduces SurgVisAgent, a multimodal large language model for surgical image enhancement.
Combines domain-specific priors, visual encoding, and chain-of-thought reasoning for versatile distortion handling.
Achieves high accuracy in distortion prediction and outperforms traditional enhancement models in robustness and quality.
Enables real-time, adaptive enhancement tailored to complex surgical visual distortions.
Agent-as-Tool: A Study on the Hierarchical Decision Making with Reinforcement Learning
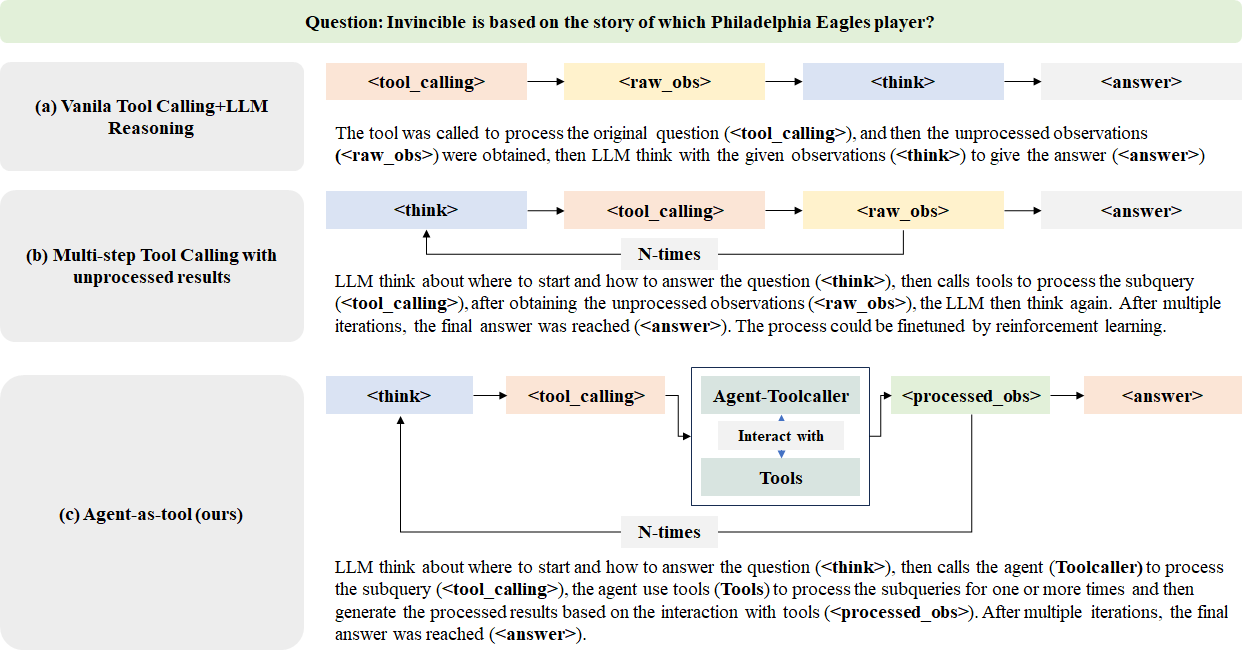
Image from arXiv paper.
What’s the research question?
How can hierarchical decision-making frameworks improve the performance of reinforcement learning agents in multi-hop reasoning tasks?
What did the authors do?
- Introduced the Agent-as-Tool framework, which separates reasoning and tool invocation into two components: a high-level Planner and a Toolcaller.
- The Planner, a language model, handles high-level reasoning and decision-making, generating natural language instructions for tool use and internal thought processes, wrapped in ... tags.
- The Toolcaller executes external actions (e.g., web searches) based on Planner instructions and returns structured observations wrapped in ... tags.
- This separation simplifies optimization and improves reasoning accuracy by decoupling complex decision steps.
- Used Generalized Reinforcement Policy Optimization (GRPO) to fine-tune the Planner, balancing reward maximization with regularization via KL divergence.
- Masked observations during training to prevent reward leakage and focused on reward signals for correct and well-formatted answers.
- Trained on a small dataset of 180 samples with multiple rollouts and tool calls to demonstrate efficiency.
What did they find?
- Achieved state-of-the-art results on the Bamboogle dataset with an Exact Match (EM) of 63.2% and Cover EM of 75.2%.
- Outperformed baselines like Search-R1 by 4.8% in EM and 3.2% in CEM.
- Improved performance on other multi-hop reasoning datasets such as HotpotQA, 2WikiMultiHopQA, and MuSiQue, with an average EM increase of 2.5% and CEM increase of 2.3%.
- Qualitative analysis showed that hierarchical decoupling enhanced reasoning clarity, question decomposition, and structured thought.
- Limitations include reliance on small training datasets and potential challenges in scaling to more complex toolsets.
Why does this matter?
- Demonstrates that hierarchical decision-making can significantly boost reinforcement learning agents' ability to perform complex, multi-step reasoning tasks.
- Decoupling reasoning from tool invocation improves clarity, efficiency, and interpretability of agent actions.
- Offers a scalable and resource-efficient approach, suitable for settings with limited training data or computational resources.
- Has broad applications in open-domain question answering, scientific research, and other areas requiring complex external tool use and multi-hop reasoning.
Key Points
Hierarchical agent architecture separates reasoning and tool invocation for better decision clarity.
Uses language-model-based Planner and external Toolcaller for structured reasoning and actions.
Achieves state-of-the-art results on multi-hop reasoning benchmarks with small training data.
Enhances reasoning transparency and efficiency in reinforcement learning agents.
Integrating Large Language Models in Financial Investments and Market Analysis: A Survey
What’s the research question?
How can large language models (LLMs) be effectively integrated into financial investment and market analysis to improve decision-making and prediction accuracy?
What did the authors do?
This paper presents a comprehensive survey of recent research on applying LLMs to finance, structured around four main frameworks:
LLM-based Frameworks and Pipelines: Implement systematic architectures for financial analysis using LLMs.
Hybrid Integration Methods: Combine traditional financial models with LLM capabilities to leverage strengths of both.
Fine-Tuning and Adaptation Approaches: Customize LLMs for specific financial tasks through techniques like Parameter-Efficient Fine-Tuning (PEFT) and instruction-based training.
Agent-Based Architectures: Use multiple AI agents working collaboratively for complex decision-making scenarios.
They evaluate models such as GPT-4, GPT-3.5, LLaMA, and FinBERT across diverse datasets including stock indices (e.g., S&P 500), social media sentiment (Twitter stock data), and proprietary financial reports. The review covers advanced techniques like Retrieval-Augmented Generation (RAG), Chain-of-Thought (CoT) reasoning, and In-Context Learning (ICL).
What did they find?
Integrating LLMs with traditional financial analysis methods significantly enhances predictive accuracy and decision quality:
The MarketSenseAI framework achieved up to 72% cumulative returns in stock selection tasks.
The Ploutos model provided interpretable predictions of stock movements, aiding transparency.
LLMs like GPT-4 and LLaMA outperformed previous models in risk assessment, sentiment analysis, and financial forecasting.
Fine-tuning techniques such as LoRA improved model relevance and efficiency.
Agent-based architectures like Alpha-GPT 2.0 and FINCON enabled adaptive, collaborative decision-making that surpassed traditional approaches.
Limitations include the need for careful fine-tuning to avoid overfitting and the computational costs associated with large models.
Why does this matter?
This survey underscores the transformative potential of LLMs in finance. By effectively processing unstructured data sources—such as news, social media, and reports—LLMs can generate interpretable insights and adapt to rapidly changing market conditions. Their integration with traditional models can lead to more robust, transparent, and adaptive investment strategies, ultimately helping investors and analysts make better-informed decisions in complex financial environments. This work points toward a future where AI-driven market analysis becomes more powerful, flexible, and accessible.
Key Points
LLMs can significantly improve financial prediction accuracy when integrated with traditional analysis techniques.
Advanced methods like Retrieval-Augmented Generation and Chain-of-Thought reasoning enhance model reasoning and relevance.
Agent-based architectures enable collaborative and adaptive decision-making outperforming classic models.
The survey highlights the importance of fine-tuning and specialized architectures for financial applications.