- TensorTeach's Newsletter
- Posts
- Reasoning Revolution: How RL Is Supercharging Language Models
Reasoning Revolution: How RL Is Supercharging Language Models
TensorTeach AI
July 18, 2025
From Roots to Rewards: Dynamic Tree Reasoning with RL
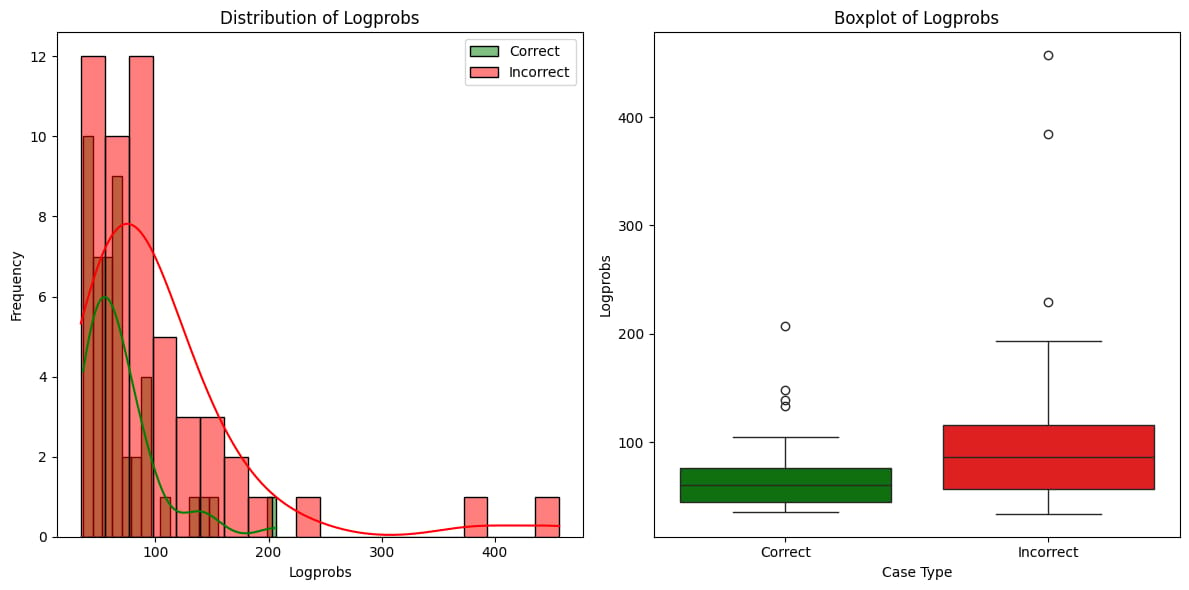
Image from arXiv paper.
What’s the research question?
How can reinforcement learning be used to dynamically construct and navigate reasoning trees in large language models for improved efficiency and accuracy?
What did the authors do?
The authors developed a novel framework that combines reinforcement learning (RL) with dynamic tree-based reasoning for large language models (LLMs):
Model the reasoning process as a Markov Decision Process (MDP), where each node in a reasoning tree represents a subproblem or question.
Design actions that include decomposing questions into sub-questions, retrieving relevant information, reformulating questions, directly answering, and resampling nodes.
Use Deep Q-Networks (DQN) to learn policies that select actions maximizing answer accuracy while minimizing computational cost.
Experiment with different state representations: question-only, transformer-encoded states, and enriched states incorporating answer confidence scores and embeddings.
Allow the agent to adapt its reasoning strategy dynamically during inference, choosing between deep decomposition and direct answering based on learned rewards.
What did they find?
The RL-guided dynamic tree reasoning approach achieved strong results across multiple datasets:
On HotpotQA, the Resampling variant reached 69.6% accuracy while reducing the number of LLM calls, demonstrating improved efficiency.
On 2WikiMultihopQA, it achieved 75.6% accuracy, outperforming static baselines like ProbTree and Greedy Solver.
On Musique, it reached 45% accuracy, showing robustness across diverse knowledge-intensive tasks.
The transformer-encoded state variant excelled on HotpotQA with 62.2% accuracy using 144 calls.
The models dynamically adapted their reasoning strategies: favoring deeper decompositions when accuracy was prioritized and more direct answers when efficiency was critical.
Limitations include the complexity of training RL agents and potential challenges in scaling to even larger or more diverse reasoning tasks.
Why does this matter?
This work introduces a flexible, RL-based framework that enables large language models to adaptively construct and navigate reasoning trees during inference. By balancing accuracy and computational efficiency dynamically, it advances the development of more intelligent and resource-aware AI systems. This approach bridges the gap between static hierarchical reasoning and adaptive problem-solving, opening new avenues for complex question answering, multimodal reasoning, and real-world AI applications where efficiency and accuracy are both critical. Its ability to learn and optimize reasoning strategies on the fly makes it a significant step toward more autonomous and intelligent AI agents.
Key Points
Introduces a reinforcement learning framework for dynamic Tree-of-Thought reasoning in LLMs.
Models reasoning as a Markov Decision Process with actions like decomposition, retrieval, reformulation, and direct answering.
Achieves state-of-the-art accuracy and efficiency on multiple knowledge-intensive datasets.
Enables adaptive reasoning strategies that balance accuracy and computational cost.
Scaling Up RL: Unlocking Diverse Reasoning in LLMs via Prolonged Training
What’s the research question?
How does prolonged reinforcement learning (RL) training influence the reasoning abilities, stability, and generalization of small language models across a variety of challenging tasks?
What did the authors do?
The authors explored how extending RL training duration affects small language models by:
Using a diverse set of reasoning tasks with verifiable reward signals, including math, coding, STEM questions, logical puzzles, and instruction following.
Applying a core RL algorithm called Group Relative Policy Optimization (GRPO), which optimizes group scores without relying on a critic model, using a clipped objective to stabilize learning.
Implementing techniques from Decoupled Advantage Policy Optimization (DAPO) to prevent entropy collapse, such as decoupled clipping and dynamic prompt sampling.
Adding a KL divergence penalty between the current policy and a reference policy to maintain exploration and prevent overfitting.
Periodically resetting the reference policy to encourage continued exploration and avoid overfitting to recent data.
Staging the training process with interventions like reward shaping and adjusting context window sizes based on validation performance.
Initializing the model from a strong baseline (DeepSeek-R1-Distill-Qwen-1.5B) and training on high-performance hardware (4 NVIDIA H100 GPUs) for 16,000 GPU hours.
What did they find?
The study yielded several notable results:
The trained model significantly outperformed baselines across multiple reasoning domains: +14.7% on math, +13.9% on coding, +54.8% on logic puzzles, +25.1% on STEM questions, and +18.1% on instruction following.
Ablation studies revealed that key training techniques—such as using a high rollout temperature, decoupled clipping, and reference policy resets—were crucial for improving stability and performance.
The model surpassed domain-specific specialized models in math and coding while maintaining a broad, general-purpose reasoning ability.
Limitations include the computational cost of prolonged training and the need for careful tuning of RL-specific hyperparameters to balance exploration and exploitation.
Why does this matter?
This work demonstrates that small language models can achieve substantial improvements in complex reasoning tasks through carefully designed, prolonged RL training. The introduced techniques effectively address common RL challenges like entropy collapse and overfitting, enabling models to learn more diverse and robust reasoning skills. By narrowing the gap between general-purpose and specialized reasoning models, this approach paves the way for more resource-efficient AI systems capable of tackling a wide range of real-world problems without relying on massive model sizes. This advancement has broad implications for developing smarter, more adaptable AI agents that can reason, solve problems, and follow instructions across multiple domains.
Key Points
Prolonged RL training with advanced techniques enhances reasoning abilities of small language models.
Techniques like decoupled clipping, dynamic prompt sampling, and reference policy resets improve stability and exploration.
The approach outperforms specialized models in math and coding while maintaining generality.
Addresses RL challenges, making reasoning training more effective and resource-efficient.
EXAONE 4.0: Unified Large Language Models Integrating Non-reasoning and Reasoning Modes
What’s the research question?
How can a large language model effectively unify non-reasoning and reasoning modes to enhance usability and reasoning performance?
What did the authors do?
The authors developed EXAONE 4.0, a large language model designed to combine two key capabilities: non-reasoning (e.g., language understanding, instruction following) and reasoning (e.g., math, logic). Their approach included:
Hybrid architecture: Combining local and global attention mechanisms to efficiently process extremely long contexts up to 128,000 tokens.
Two-stage context extension: Extending context length from 4K to 32K tokens, then to 128K tokens, validated through iterative testing.
Unified training dataset: Using a balanced mix of non-reasoning and reasoning data at a 1.5:1 token ratio.
Hybrid reward reinforcement learning: Combining verifiable correctness rewards, human preference rewards, and language consistency rewards.
Fine-tuning and policy optimization: Starting with supervised learning, then refining with reinforcement learning using AGAPO, an algorithm that calculates advantages at both group and global levels to improve policy updates.
Preference learning: Merging correctness and human preferences to teach the model nuanced behaviors aligned with user expectations.
What did they find?
EXAONE 4.0 demonstrated strong performance across multiple benchmarks:
Math and coding: Achieved 85.3% accuracy on AIME 2025 and 72.6% on LiveCodeBench v5, outperforming open-weight models of similar size.
Long-context understanding: Scored 94.06% on HELMET Recall and 94.85% on RULER at 128K tokens, showing excellent handling of extended contexts.
Tool use and instruction following: Matched or surpassed larger models in Tau-Bench and BFCL-v3; achieved 57.8% accuracy in IFEval and 83.7% in instruction following.
Strengths: The dual-mode architecture enabled the model to excel in both deep reasoning and quick instruction tasks.
Limitations: The paper does not specify potential challenges such as computational cost or generalization to other modalities beyond text.
Why does this matter?
EXAONE 4.0 pushes the boundaries of large language models by effectively integrating non-reasoning and reasoning capabilities within a single unified system. Its innovative hybrid attention and long-context processing enable it to handle complex tasks that require both quick comprehension and deep logical inference. This advancement opens new possibilities for AI applications that demand versatile understanding, such as intelligent assistants, code generation, mathematical problem-solving, and tool use. By demonstrating how to balance usability with sophisticated reasoning, EXAONE 4.0 provides a valuable blueprint for future models aiming to operate seamlessly across diverse AI tasks.
Key Points
Unified model combining non-reasoning and reasoning modes improves versatility and performance.
Hybrid attention and long-context processing enable handling of up to 128K tokens.
Reinforcement learning with hybrid rewards refines model behavior to align with correctness and human preferences.
Strong results on math, coding, long-context understanding, and tool use benchmarks.
VisionThink: Smart and Efficient Vision Language Model via Reinforcement Learning
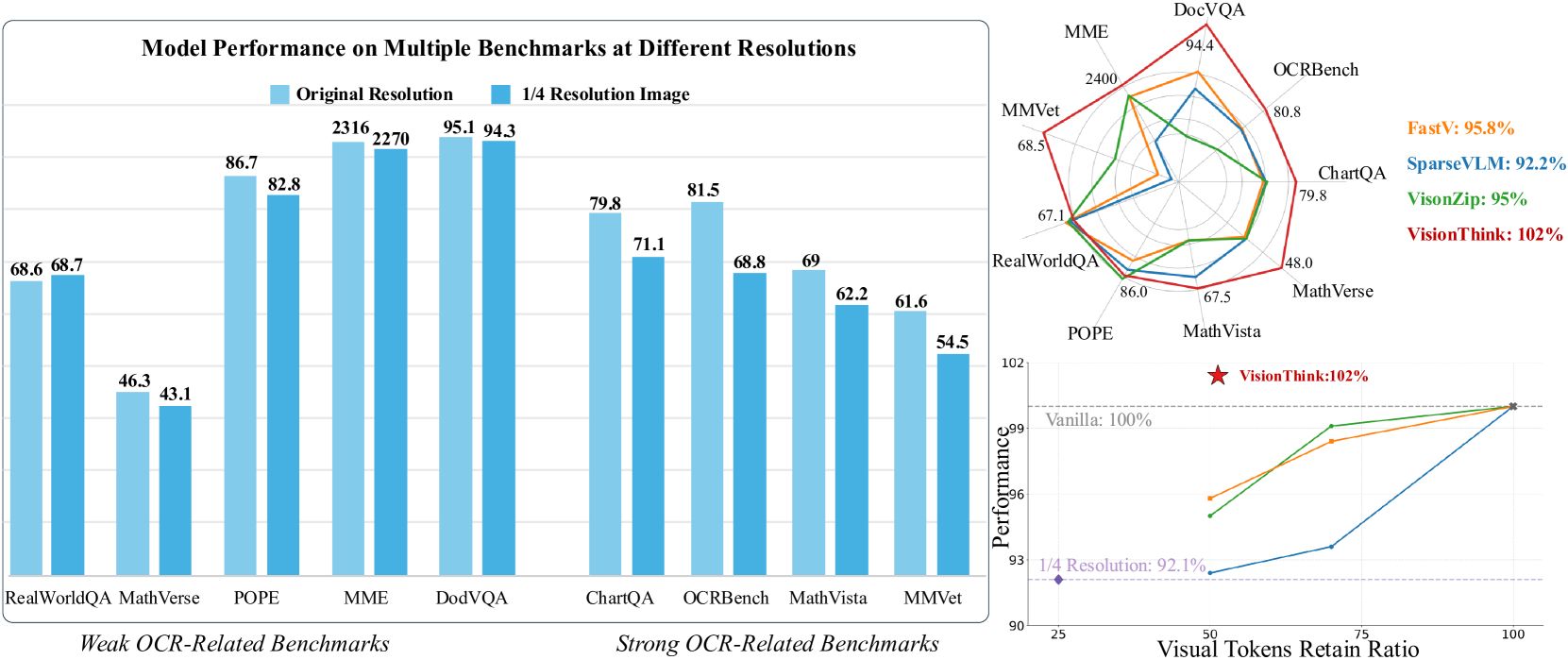
Image from arXiv paper.
What’s the research question?
How can a vision-language model dynamically decide when to request high-resolution images to optimize both task performance and computational efficiency?
What did the authors do?
- Developed VisionThink, a vision-language model that starts with a downsampled image and uses reinforcement learning to decide whether to request a higher-resolution version.
- Implemented a novel LLM-as-Judge training strategy, where a large language model evaluates the correctness of outputs and guides learning.
- Designed a multi-turn training process allowing the model to request high-res images and generate improved responses based on enhanced inputs.
- Created a balanced dataset of 130,000 QA pairs, some requiring high-res images and others not.
- Integrated visual token compression and a decision-making mechanism for image upscaling, optimized through reinforcement learning.
What did they find?
- Achieved a 7.9% improvement on the MMVet benchmark and scored 71.2 on MathVista, outperforming existing open-source models.
- Demonstrated a 70% reduction in visual tokens on average while maintaining high accuracy.
- Showed that selectively upscaling images led to significant efficiency gains, with up to 100% speed-ups on certain OCR-dependent tasks.
- Limitations include reliance on a fixed threshold for decision-making, which may not generalize well, and dependence on the external language model for evaluation, potentially introducing bias.
Why does this matter?
- Innovative adaptive approach: Enables vision-language models to make case-by-case decisions about visual input resolution, balancing accuracy and efficiency.
- Practical impact: Reduces computational costs, making multimodal AI more accessible and environmentally sustainable.
- Broader applications: Enhances real-time systems like robotics, autonomous vehicles, and translation by efficiently processing visual data.
- Research contribution: Provides a blueprint for integrating reinforcement learning with multimodal reasoning, encouraging future adaptive AI systems.
Key Points
VisionThink dynamically requests high-resolution images using reinforcement learning guided by a large language model.
Achieves significant efficiency gains with up to 70% reduction in visual tokens and 100% speed-ups on some tasks.
Outperforms existing models on multiple vision-language benchmarks, demonstrating the value of adaptive visual input resolution.
Introduces a novel training strategy combining multi-turn interactions and LLM-based evaluation.
Learning and Reasoning with Model-Grounded Symbolic Artificial Intelligence Systems
Image from arXiv paper.
What’s the research question?
Can instruction-tuned large language models (LLMs) be reinterpreted as model-grounded symbolic AI systems to improve their reasoning and learning capabilities?
What did the authors do?
The authors proposed a novel framework that treats instruction-tuned LLMs as symbolic AI systems grounded in their internal representations. Key components include:
Model-grounded symbolic interpretation: Viewing natural language prompts as symbolic representations grounded in the model's internal state.
Iterative prompt refinement: Refining model behavior through repeated interactions involving critiques and structured memory.
Critique-driven updates: Using a judge model to evaluate outputs and generate symbolic corrections to guide learning.
Algorithm formalization: An iterative process involving model initialization, evaluation, symbolic correction generation, and refinement, contrasting with traditional differentiable training.
What did they find?
Preliminary experiments demonstrated that this approach enhances reasoning reliability, adaptability, and sample efficiency on axiomatic deductive tasks:
Improved accuracy on mathematical problems, with GPT-4o gaining 2.11% and Gemini-1.5-Flash gaining 6.67% at certain context sizes.
Metatuning with a small set of examples significantly boosted performance on unseen problems.
Compared to backpropagation-based training, this method does not require differentiability or large datasets, offering better data efficiency and convergence guarantees.
Limitations include the need for careful design of critique and symbolic correction mechanisms and initial validation on specific reasoning tasks.
Why does this matter?
This work offers a fresh perspective on how instruction-tuned LLMs can be viewed as symbolic systems grounded in their internal representations, bridging neural and symbolic AI. The iterative prompt refinement approach enhances reasoning and learning without heavy reliance on gradient-based training or vast data, potentially leading to more robust, interpretable, and adaptable AI systems. This could impact applications requiring complex reasoning, such as mathematical problem-solving, scientific discovery, and logical inference, by enabling models to learn and reason more effectively through structured interactions grounded in their internal knowledge.
Key Points
Reinterprets instruction-tuned LLMs as model-grounded symbolic AI systems grounded in internal representations.
Introduces an iterative prompt refinement framework with critique-driven symbolic corrections.
Enhances reasoning accuracy and sample efficiency on deductive tasks compared to traditional training.
Offers a new pathway to combine neural and symbolic AI for more robust and interpretable systems.
Argus: Leveraging Multiview Images for Improved 3-D Scene Understanding With Large Language Models
What’s the research question?
How can multi-view images be effectively integrated into large language models to improve 3D scene understanding?
What did the authors do?
The authors developed Argus, a novel multimodal framework that combines multiple views of a scene with large language models (LLMs) to enhance 3D understanding. Its key components include:
Fusion module: Aggregates multi-view images and camera poses into view-as-scene features using a 2D Q-Former.
3D-aware Q-Former: Interacts with both view-as-scene features and 3D point cloud features via self-attention and cross-attention to produce 3D-aware embeddings.
Large Language Model (LLM): A frozen LLM that takes the 3D-aware embeddings as input for downstream reasoning tasks.
Training strategy: Pre-trains the 3D-aware Q-Former on tasks like 3D question answering, scene captioning, embodied dialogue, and planning, followed by joint pre-training of the fusion module and Q-Former, then fine-tuning on specific tasks.
What did they find?
Argus achieved state-of-the-art performance on multiple 3D understanding benchmarks, including:
3D question answering (3D-QA): EM of 25.9 and CIDEr of 79.3, outperforming previous models like 3D-LLM and LL3DA.
3D visual grounding (3D-VG), embodied dialogue, scene description, and embodied planning tasks.
Key insights include:
The fusion module and 3D-aware Q-Former significantly improve performance compared to ablated versions.
Using multiple views per scene yields notable gains, highlighting the importance of multi-view integration.
Limitations include reliance on high-quality multi-view data and the computational complexity of joint training.
Why does this matter?
Argus advances the field of 3D scene understanding by demonstrating how to effectively combine multi-view images with large language models. This enables more accurate and detailed reasoning about complex 3D environments, which is crucial for applications like robotics, autonomous navigation, and immersive virtual reality. By integrating rich visual information into LLMs, Argus opens new avenues for multimodal AI systems that can interpret and interact with the 3D world more intelligently.
Key Points
Introduces Argus, a multimodal framework combining multi-view images and LLMs for 3D understanding.
Uses a fusion module and 3D-aware Q-Former to generate 3D-aware embeddings from images and point clouds.
Achieves state-of-the-art results on 3D question answering, grounding, and planning benchmarks.
Highlights the importance of multi-view integration for detailed 3D scene reasoning.
Towards Concise and Adaptive Thinking in Large Reasoning Models: A Survey
What’s the research question?
How can large reasoning models (LRMs) generate more concise and adaptive reasoning processes to improve efficiency and performance?
What did the authors do?
This survey reviews recent advances in methods designed to make LRMs reason more efficiently and flexibly by balancing reasoning depth with computational cost. The authors categorize approaches into two main groups:
Training-free methods: These do not require additional training but instead manipulate inputs or model outputs to encourage concise reasoning.
Prompt-guided strategies: Use carefully crafted prompts to steer the model toward shorter, more focused reasoning chains, such as instructing the model to be concise or limit token usage.
Pipeline-based approaches: Design modular workflows that route simpler queries to smaller, faster models to save computation.
Decoding manipulation: Dynamically adjust the decoding process during inference, for example by setting token budgets or early exit checks based on confidence or semantic convergence.
Model merging: Combine long- and short-chain reasoning models via parameter interpolation to balance reasoning detail and efficiency.
Training-based methods: Fine-tune models on variable-length chain-of-thought (CoT) data so they can adaptively generate concise or elaborate reasoning depending on problem complexity. Reinforcement learning (RL) techniques are used to optimize the trade-off between reasoning length and accuracy, employing strategies like length penalties, difficulty-aware responses, and adaptive thinking modes.
Authors evaluate these methods using metrics such as accuracy, number of inference tokens, latency, speed-up ratio, and reasoning verbosity to assess efficiency and performance.
What did they find?
Key findings include:
Prompt-guided strategies effectively shorten reasoning chains but depend on the model’s ability to follow instructions accurately.
Pipeline-based approaches reduce computational costs but introduce auxiliary overheads from managing multiple models.
Decoding manipulation can dynamically shorten reasoning chains by monitoring confidence or semantic convergence, but frequent verification may offset computational savings.
Model merging balances long- and short-chain capabilities but struggles with extreme scales or highly divergent models.
Fine-tuning on variable-length CoT data improves adaptability but requires careful data curation to avoid biasing the model toward overly concise or verbose reasoning.
RL-based strategies such as length penalties and difficulty-aware responses can optimize the trade-off between efficiency and accuracy, with some methods dynamically adjusting reasoning length based on problem complexity.
Limitations noted include potential challenges in scaling some approaches to very large models and the need for standardized evaluation metrics to compare methods effectively.
Why does this matter?
Making LRMs generate more concise and adaptive reasoning processes is crucial for deploying powerful AI systems in real-world applications where computational resources and response times matter. By reducing reasoning verbosity without sacrificing accuracy, these methods can improve the efficiency of AI in domains like education (e.g., step-by-step problem solving), healthcare (e.g., diagnostic reasoning), and customer service (e.g., complex query handling). Additionally, adaptive reasoning enhances interpretability by tailoring explanation depth to user needs and problem difficulty. The survey highlights the importance of balancing reasoning detail with efficiency and provides a roadmap for future research to develop more trustworthy and practical large reasoning models.
Key Points
Survey categorizes recent methods for making large reasoning models more concise and adaptive.
Includes prompt-guided, pipeline-based, decoding manipulation, model merging, and fine-tuning approaches.
Reinforcement learning strategies optimize the trade-off between reasoning length and accuracy.
Highlights strengths, limitations, and evaluation challenges of each method.
Comprehension Without Competence: Architectural Limits of LLMs in Symbolic Computation and Reasoning
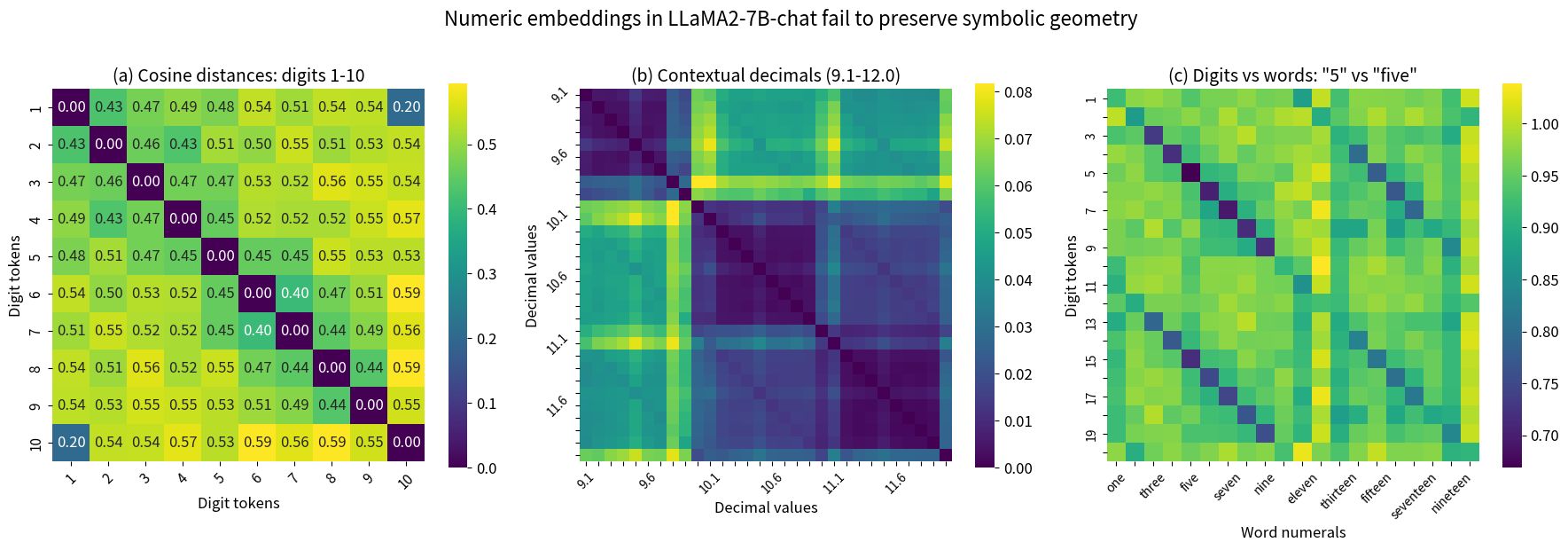
Image from arXiv paper.
What’s the research question?
This paper investigates the fundamental architectural limitations of large language models (LLMs) in performing symbolic computation and reasoning tasks, such as arithmetic and logical inference.
What did the authors do?
The authors conducted a series of controlled experiments and analyses on several prominent LLMs, including LLaMA2, Claude, and GPT-4, focusing on their ability to understand and execute symbolic tasks.
Tested models on symbolic problems like decimal multiplication and family relation inference, using both in-distribution and out-of-distribution data.
Performed layer-by-layer analysis of neural activations to understand how representations evolve through the model.
Visualized embedding spaces to examine the geometric relationship between instructional inputs and execution outputs.
Analyzed the theoretical capabilities of feed-forward neural networks (FFNs) to implement exact symbolic operations, providing formal proofs of their limitations.
Introduced the concept of the 'computational split-brain syndrome' to describe the observed dissociation between models’ ability to articulate principles and reliably execute them.
What did they find?
The study revealed a striking dissociation between LLMs’ symbolic understanding and execution abilities:
Articulation vs. execution: Models could articulate principles flawlessly but failed to execute them reliably. For example, GPT-4 achieved 95-100% accuracy on individual multiplication steps but only 5% accuracy on 5-digit problems and 0% on 10-digit problems.
Layer analysis: Representations across layers converged towards correct outputs, yet the final answers remained incorrect, indicating a disconnect between internal understanding and output generation.
Embedding visualization: Showed a clear geometric separation between instructional pathways (how models are told to perform tasks) and execution pathways (how they produce answers), confirming the instruction-execution disconnect.
Theoretical limitations: Formal proofs demonstrated that feed-forward networks cannot implement exact symbolic operations like multiplication without exponential growth in network size, highlighting an architectural bottleneck.
Why does this matter?
This work provides critical mechanistic insights into why current LLMs struggle with symbolic reasoning despite their impressive language capabilities:
Implications for AI design: Highlights the need for architectural innovations that enable models to reliably execute symbolic operations, not just articulate them, which is essential for tasks requiring precise reasoning.
Broader impact: Clarifies the limitations of LLMs in high-stakes domains like medicine and law where reliable symbolic reasoning is crucial, guiding the development of more trustworthy AI systems.
Research advancement: Introduces the 'computational split-brain syndrome' as a new diagnostic lens for understanding and addressing reasoning failures in neural networks.
Key Points
LLMs can articulate principles of symbolic tasks but fail to execute them reliably, revealing a fundamental architectural limitation.
Layer-by-layer and geometric analyses show a disconnect between instruction representations and execution outputs.
Theoretical proofs demonstrate feed-forward networks cannot efficiently implement exact symbolic operations like multiplication.
The 'computational split-brain syndrome' describes the dissociation between reasoning ability and execution fidelity in LLMs.
EmbRACE-3K: Embodied Reasoning and Action in Complex Environments
What’s the research question?
How can vision-language models be improved to better support embodied reasoning and action in complex, interactive environments?
What did the authors do?
The authors introduced EmbRACE-3K, a large-scale dataset designed to train and evaluate embodied AI agents. Key aspects include:
Dataset Composition: Over 3,000 language-guided tasks in photorealistic environments, each with egocentric visual observations, high-level instructions, and step-by-step natural language rationales.
Data Collection: Environment sampling, instruction generation using Gemini, human demonstrations, and detailed step-wise annotations to capture perception-action-reasoning dynamics.
Interactive Support: Enables online, closed-loop interaction allowing models to learn perception-conditioned decision making.
Training Pipeline: Combines supervised fine-tuning (SFT) on 2,344 high-quality trajectories to improve spatial reasoning with reinforcement learning (RL) using a rule-based reward to promote autonomous exploration and reasoning.
What did they find?
Key results demonstrate the importance of step-wise reasoning annotations:
Zero-shot performance of baseline models (GPT-4o, Gemini 2.5 Pro, Qwen2.5-VL-7B) was below 20% success rate across tasks.
Fine-tuning Qwen2.5-VL-7B with EmbRACE-3K improved success rates to 30.9% on exploration tasks and 42.4% on spatial-semantic reasoning tasks.
Multi-stage goal execution success increased from 0% (no fine-tuning) to 27.0% after training.
Models without explicit reasoning annotations (“no-thinking” models) performed worse, highlighting the value of step-wise rationales.
Why does this matter?
EmbRACE-3K advances the field of embodied AI by providing a richly annotated, multimodal dataset that captures the full perception-action-reasoning loop in complex environments. This enables models to not only interpret visual and language inputs but also reason through sequential steps to plan and execute actions effectively. The work bridges the gap between passive understanding and active interaction, paving the way for more robust embodied agents capable of spatial reasoning, goal planning, and causal understanding in real-world scenarios. Such capabilities are crucial for applications ranging from autonomous robotics to interactive virtual assistants, where intelligent agents must perceive, think, and act in dynamic settings.
Key Points
EmbRACE-3K is a large, step-wise, multimodal dataset for embodied reasoning and action.
Combines egocentric vision, language instructions, and natural language rationales in complex environments.
Fine-tuning models on EmbRACE-3K improves exploration, spatial reasoning, and multi-stage goal completion.
Explicit step-wise reasoning annotations are critical for enhancing embodied AI performance.
Warehouse Spatial Question Answering with LLM Agent 1st Place Solution of the 9th AI City Challenge Track 3
What’s the research question?
How can a large language model (LLM) agent system be designed to perform robust spatial reasoning and question answering in complex indoor warehouse environments?
What did the authors do?
The authors developed an innovative AI system that combines a large language model with specialized perception tools to answer spatial questions in warehouses:
Utilized a Gemini-2.5-Flash LLM agent with function-calling capabilities to manage multi-turn conversations and structured message history.
Integrated the LLM with three spatial API tools: distance estimation, object inclusion detection, and spatial relationship recognition.
Implemented lightweight perception models based on ResNet-50 to process RGB images and binary masks for spatial tasks:
Distance estimation model predicts the absolute distance between objects via direct regression.
Inclusion classification model determines whether one object is contained within another, trained on data from counting questions.
Preprocessed questions to align with object masks, enabling the LLM to understand mask-to-object relationships effectively.
During inference, the system parses questions, identifies relevant objects and masks, invokes spatial APIs, and iteratively refines its reasoning before generating an answer.
What did they find?
The system achieved outstanding results:
95.86% accuracy on the 2025 AI City Challenge Spatial Intelligence Warehouse benchmark.
Outperformed all other competitors, demonstrating state-of-the-art performance in object retrieval, counting, and distance estimation tasks.
Showed that integrating LLMs with specialized perception models and APIs can effectively handle complex indoor spatial reasoning challenges.
Limitations include reliance on high-quality object masks and the need for task-specific perception models, which may require additional training data.
Why does this matter?
This work pushes the boundaries of spatial understanding in AI by demonstrating a highly effective way to combine language models with perception tools for complex environments like warehouses:
Enables robots and AI agents to better navigate, search, and reason about their surroundings in indoor spaces, improving automation and logistics.
Offers a data-efficient alternative to large-scale multi-modal language model finetuning by leveraging specialized perception APIs.
Potentially accelerates the development of intelligent warehouse robots, inventory management systems, and other spatially-aware AI applications.
Highlights the importance of integrating structured API tools with LLMs for enhanced reasoning capabilities beyond pattern matching.
Key Points
First-place solution in AI City Challenge Track 3 for warehouse spatial question answering.
Combines Gemini-2.5-Flash LLM with lightweight ResNet-50 perception models and spatial APIs.
Achieves 95.86% accuracy, outperforming all competitors in complex indoor spatial reasoning tasks.
Advances multimodal LLM-agent integration for robust spatial understanding in robotics and AI.