- TensorTeach's Newsletter
- Posts
- OpenAI Launches GPT-5 + Relevant Research: Tool-Using AI Beats Claude, Symbolic Reasoning Benchmark Debuts, and Multimodal Models Shrink
OpenAI Launches GPT-5 + Relevant Research: Tool-Using AI Beats Claude, Symbolic Reasoning Benchmark Debuts, and Multimodal Models Shrink
TensorTeach AI
August 08, 2025
On August 7, OpenAI rolled out GPT-5, replacing GPT-4 and 4o as the default in ChatGPT and the API. It’s not just a bigger model—it’s a router that switches between faster or deeper reasoning modes, supports up to 256K–1M tokens, and adds Gmail, Calendar, and Microsoft Copilot integrations. Developers get new controls like verbosity and reasoning_effort, while enterprises like Amgen are already deploying it.
The launch was bumpy. Routing bugs made answers seem worse at first, older models vanished overnight, and stricter usage limits sparked backlash on Reddit. Sam Altman has promised fixes, but the rollout shows that scaling intelligence is as much about control and reliability as raw capability.
That’s exactly the theme running through this week’s research. Light-IF tackles GPT-5’s core promise—better instruction-following—showing small models can outperform larger ones through self-checking, entropy-controlled training, and synthetic prompts. MulCoT-RD echoes GPT-5’s push for multimodal reasoning, distilling complex text-image sentiment tasks into a 3B-parameter model that beats bigger rivals. SymbolBench explores symbolic reasoning over time series—key for scientific and financial applications—where GPT-5-class models shine in regression and causal discovery but still struggle with combinatorial logic. ToolTrain mirrors GPT-5’s tool-use abilities, using RL to improve code issue search beyond Claude-3.7. And MERA advances meta-cognition, teaching models when to think harder and when to stop—a skill that could make GPT-5’s router far more effective.
Key AI Research From This Past Week
Light-IF: Endowing LLMs with Generalizable Reasoning via Preview and Self-Checking for Complex Instruction Following
What’s the research question?
How can we improve the instruction-following capabilities of large language models (LLMs) to better adhere to complex and strict instructions?
What did the authors do?
The authors introduced a novel framework called Light-IF that enhances LLMs' reasoning and instruction-following abilities through several innovative components:
Prompt synthesis: Generated diverse prompts with varying difficulty and complexity using seed prompts, self-instruct expansion, complex constraints, and filtering.
Zero-shot reinforcement learning (Zero-RL): Applied to a "lazy-thinking" model to encourage effective reasoning behaviors by rewarding correctness and response length.
Thinking pattern extraction: Identified and promoted high-quality responses that demonstrated effective reasoning strategies.
Entropy-preserving supervised fine-tuning (Entropy-SFT): Fine-tuned the model while maintaining entropy levels to foster exploration and prevent premature convergence.
Token-wise entropy-adaptive reinforcement learning (TEA-RL): Further refined reasoning by adaptively controlling entropy at the token level during training.
What did they find?
The Light-IF models showed remarkable improvements in instruction-following benchmarks:
Performance surpassing larger models: The Light-IF-32B model outperformed both open-source and closed-source models like DeepSeek-R1 and Doubao-1.6 on multiple benchmarks.
Competitive results with small models: The Light-IF-1.7B-Zero model, trained solely on synthetic data without external APIs, achieved competitive accuracy, demonstrating the effectiveness of the reasoning mechanisms.
Ablation studies: Confirmed that each component contributed to the overall performance, with the full framework achieving the highest scores.
Why does this matter?
This work pushes the boundaries of what smaller LLMs can achieve in instruction-following and reasoning:
Democratization of AI capabilities: Enables smaller, more accessible models to perform at or above the level of larger, resource-intensive models, lowering barriers to deployment and experimentation.
Advancement in reasoning techniques: Introduces effective previewing and self-checking mechanisms that improve model accuracy and reliability on complex tasks.
Broader impact: The entropy control and reasoning strategies can inform future research on model alignment, interpretability, and robustness, benefiting the wider AI community.
Key Points
Light-IF combines prompt synthesis, self-checking, and advanced reinforcement learning to improve instruction-following in LLMs.
Models trained with Light-IF outperform larger counterparts on multiple benchmarks, demonstrating strong reasoning capabilities.
Entropy-preserving and token-wise adaptive training promote diverse and effective reasoning behaviors.
The approach is effective even without external APIs or large-scale training data, making it accessible and scalable.
Resource-Limited Joint Multimodal Sentiment Reasoning and Classification via Chain-of-Thought Enhancement and Distillation
What’s the research question?
How can lightweight models effectively perform joint multimodal sentiment reasoning and classification in environments with limited computational resources?
What did the authors do?
The authors developed a novel framework called MulCoT-RD to enable small, resource-efficient models to understand and classify sentiment across multiple modalities (like text and images). Their approach includes:
Hierarchical teacher-assistant-student paradigm: Using a powerful multimodal large language model (MLLM) as a teacher to generate detailed reasoning data, an assistant model to learn structured reasoning and sentiment classification jointly, and a lightweight student model to deploy in resource-constrained settings.
Structured Chain-of-Thought (CoT) prompting: The teacher model decomposes complex sentiment tasks into subtasks, provides reasoning guidance, mediates conflicts, and controls retries to produce high-quality reasoning datasets.
Multi-task learning for the assistant model: The assistant learns to generate both sentiment labels and reasoning chains simultaneously, optimizing reasoning quality and classification accuracy together.
Knowledge distillation: The assistant model synthesizes high-quality reasoning and soft labels (probabilistic outputs) to train the lightweight student model, which learns from both hard ground-truth labels and soft assistant predictions.
Joint optimization: Balancing classification accuracy and reasoning quality through combined loss functions and hyperparameter tuning.
What did they find?
The MulCoT-RD framework achieved impressive results:
Superior performance: Outperformed state-of-the-art models on coarse-grained multimodal sentiment analysis tasks (MSA and MASC datasets).
High-quality reasoning: The assistant model's reasoning chains achieved cosine similarity > 90% and BLEU scores > 35, indicating clear and accurate explanations.
Efficient lightweight student: The 3-billion-parameter student model surpassed larger models like Emotion-LLaMA in accuracy and F1 scores, demonstrating strong performance with fewer resources.
Robustness and generalization: Ablation studies confirmed the importance of multimodal integration, structured CoT prompts, and hierarchical distillation. The framework also worked well across different backbone models, including Flan-T5-based architectures.
Limitations: While results are promising, the approach relies on high-quality teacher-generated data and may require careful tuning of hyperparameters for different tasks.
Why does this matter?
This work significantly advances the field of resource-efficient multimodal sentiment analysis by enabling small models to perform complex reasoning and classification tasks that typically require large, computationally intensive models. The hierarchical distillation and structured Chain-of-Thought strategies improve interpretability, robustness, and accuracy, making multimodal AI more accessible and trustworthy in real-world applications where resources are limited. This approach bridges the gap between high-performance large models and deployable lightweight systems, opening new possibilities for sentiment analysis in mobile devices, embedded systems, and other constrained environments, ultimately broadening the impact of multimodal AI technologies.
Key Points
Introduces MulCoT-RD, a hierarchical teacher-assistant-student framework for resource-limited multimodal sentiment reasoning and classification.
Uses structured Chain-of-Thought prompts to decompose tasks and improve reasoning quality.
Employs multi-task learning and knowledge distillation to train a lightweight student model that outperforms larger models.
Achieves high reasoning quality and classification accuracy on multiple multimodal sentiment datasets.
Can Large Language Models Adequately Perform Symbolic Reasoning Over Time Series?
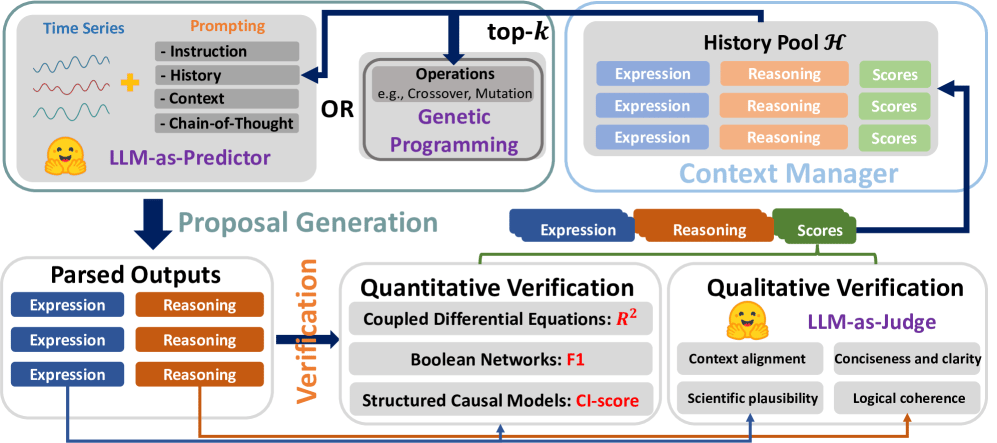
Image from arXiv paper.
What’s the research question?
Can Large Language Models (LLMs) perform symbolic reasoning effectively over time series data, which involves understanding and manipulating sequences of data points that change over time?
What did the authors do?
The authors developed a comprehensive benchmark called SymbolBench to evaluate LLMs' ability to perform symbolic reasoning on time series data across three challenging tasks:
Multivariate symbolic regression: Discovering mathematical expressions that describe relationships in multiple time series variables.
Boolean network inference: Inferring logical relationships between binary variables over time, a complex combinatorial problem.
Causal discovery: Identifying cause-and-effect relationships from temporal data.
They integrated LLMs with genetic programming, an evolutionary algorithm that iteratively refines hypotheses, through a unified framework involving:
Proposal Generation: LLMs generate candidate expressions or hypotheses.
Verification: Assessing the quality of these hypotheses against data.
Context Management: Selecting relevant context to improve reasoning in subsequent iterations.
Various prompting strategies were tested, including:
Naive prompts
Base prompts
Contextual prompts
Chain-of-Thought (CoT) reasoning prompts
They evaluated multiple LLMs, such as GPT-4 and Llama, on datasets with varying complexity and domain relevance, measuring performance both within and outside the training distribution.
What did they find?
The study revealed nuanced strengths and limitations of LLMs in symbolic reasoning over time series:
LLMs outperformed traditional symbolic reasoning baselines in multivariate symbolic regression and causal discovery, demonstrating strong capabilities in these areas.
In Boolean network inference, a more combinatorial and logical task, LLMs lagged behind specialized algorithms.
Performance declined as task complexity increased and when evaluated on out-of-distribution data, highlighting challenges in generalization.
Using contextual grounding—providing relevant prior information—improved both accuracy and robustness across tasks.
Hybrid approaches that combined LLMs with genetic programming further enhanced results, leveraging the strengths of both.
Limitations include the difficulty of scaling to very complex logical networks and the need for better out-of-distribution generalization.
Why does this matter?
This work advances our understanding of how large language models can be applied beyond natural language to complex scientific and engineering problems involving time series data. By providing a benchmark and framework for evaluating symbolic reasoning in this domain, it guides future research toward more capable and interpretable AI systems. Such capabilities are crucial for:
Scientific discovery: Automating the discovery of mathematical models and causal relationships from experimental data.
Data analysis: Extracting interpretable rules from complex temporal datasets in fields like biology, finance, and engineering.
AI interpretability: Enhancing trust and transparency by generating human-readable symbolic hypotheses.
Overall, this study highlights both the promise and current limitations of LLMs in symbolic reasoning over time series, paving the way for more robust and generalizable AI tools in scientific and real-world applications.
Key Points
Introduces SymbolBench, a benchmark for evaluating LLMs on symbolic reasoning over time series data.
Combines LLMs with genetic programming to generate, evaluate, and refine hypotheses iteratively.
LLMs excelled in symbolic regression and causal discovery but struggled with Boolean network inference.
Contextual grounding and hybrid LLM-GP approaches improved reasoning accuracy and generalization.
Tool-integrated Reinforcement Learning for Repo Deep Search
What’s the research question?
Can reinforcement learning be effectively combined with large language models to improve the accuracy and efficiency of locating issues within software repositories?
What did the authors do?
The authors introduced a novel framework called ToolTrain that integrates reinforcement learning (RL) with large language models (LLMs) to enhance issue localization in code repositories. Their approach involves several key steps:
Developed RepoSearcher: A lightweight agent equipped with simple retrieval tools such as GetRepoStructure (to understand repository layout) and SearchFunction (to find relevant code snippets).
Supervised Fine-Tuning (SFT): Used rejection sampling to train LLMs on high-quality trajectories where only successful tool-use sequences (e.g., correctly identifying relevant functions) were kept, improving the model’s ability to generate effective tool calls.
Reinforcement Learning (RL) Optimization: Employed rule-based RL where the model generated multiple tool-use trajectories per issue. These trajectories were scored using nDCG@k (a ranking metric) against ground-truth answers, providing reward signals to refine the model’s tool invocation policies.
Iterative Improvement: Combined SFT and RL training to enable the LLM to learn complex multi-hop reasoning and effective tool use for issue localization.
What did they find?
The ToolTrain framework led to significant performance improvements:
State-of-the-art issue localization: The 32-billion-parameter model achieved a function-level Recall@5 of 68.55%, outperforming Claude-3.7-Sonnet’s 66.38%.
Better end-to-end issue resolution: The same model reached a 31.60% resolution rate, surpassing other existing approaches.
Ablation studies: Demonstrated that combining supervised fine-tuning with reinforcement learning yielded the best results, highlighting the importance of hybrid training strategies.
Limitations: The study focused on specific retrieval tools and benchmark datasets; real-world variability and larger codebases may pose additional challenges.
Why does this matter?
This work pushes forward the integration of reinforcement learning with large language models in the domain of software engineering. By enabling LLMs to better reason across multiple steps and effectively invoke tools, the approach significantly improves the accuracy and efficiency of issue localization—a critical task for maintaining and developing large codebases. The hybrid training strategy demonstrated here can be adapted to other agent-based tasks that require complex tool use and multi-hop reasoning, opening new avenues for intelligent automation in software development and beyond.
Key Points
Introduced ToolTrain, a hybrid training framework combining supervised fine-tuning and reinforcement learning for LLMs in issue localization.
Used simple retrieval tools and reward-based RL to teach the model effective multi-hop reasoning and tool invocation.
Achieved state-of-the-art performance on benchmark issue localization tasks, outperforming existing models.
Demonstrated the potential of combining RL and LLMs to improve complex reasoning and tool use in real-world AI applications.
From “Aha Moments” to Controllable Thinking: Toward Meta-Cognitive Reasoning in Large Reasoning Models via Decoupled Reasoning and Control
What’s the research question?
How can large reasoning models be enhanced with meta-cognitive abilities to regulate their reasoning processes effectively?
What did the authors do?
The authors introduced a novel framework called Meta-cognitive Reasoning Architecture (MERA) that decouples reasoning and control in large language models to improve their self-regulation and efficiency. Key elements include:
Decoupled Architecture: Separates reasoning (the step-by-step problem solving) from control (deciding when to revise, continue, or terminate reasoning).
Control-Takeover Mechanism: Uses auxiliary large language models (LLMs) to generate control signals at critical decision points during reasoning.
Structured Fine-Tuning: Employs explicit reasoning and control tags to clearly distinguish reasoning steps from control signals, enabling better learning of the separation.
Control-Segment Policy Optimization (CSPO): Combines segment-wise Group Relative Policy Optimization (GRPO) with control masking to optimize control behavior while reducing irrelevant content interference.
Training Procedure: Alternates between reasoning and control segments, with control signals guiding whether to continue, revise, or terminate reasoning steps.
What did they find?
MERA demonstrated significant improvements over baseline models and previous approaches:
Higher accuracy: On the DeepSeek-R1-Distill-Qwen-1.5B benchmark, accuracy improved from 58.6% to 62.5%.
Reduced reasoning length: Average token count decreased from 8,379 to 4,583, indicating more concise reasoning.
Better generalization: Effectively reduced reasoning length in non-mathematical tasks without sacrificing accuracy.
Outperformed dual-model approaches: The integrated control and reasoning architecture was more efficient and accurate than methods that alternate reasoning between separate models.
Limitations: The approach requires careful design of control signals and may involve additional training complexity. Further testing on diverse reasoning tasks is needed to confirm robustness.
Why does this matter?
This work advances the development of autonomous, self-regulating AI reasoning systems by explicitly modeling how models can control their own thinking processes. The decoupling of reasoning and control enables models to avoid overthinking, improve efficiency, and produce clearer, more targeted outputs. Such meta-cognitive capabilities are crucial for building AI that can adaptively manage complex problem-solving, enhance explainability, and generalize better across diverse tasks. This framework paves the way for more robust and intelligent reasoning agents that can better mimic human-like reflective thinking and decision-making.
Key Points
Decoupling reasoning and control improves self-regulation and efficiency in large language models.
MERA uses auxiliary models to generate control signals guiding reasoning steps.
Control signals help models decide when to revise, continue, or stop reasoning, reducing overthinking.
Significant accuracy and reasoning length improvements demonstrated on benchmark tasks.