- TensorTeach's Newsletter
- Posts
- OpenAI Government AI, Agentic AI Expansion, Davos AI Debate, Next-Gen AI Hardware
OpenAI Government AI, Agentic AI Expansion, Davos AI Debate, Next-Gen AI Hardware
Federal AI adoption accelerates, autonomous agents move toward real-world deployment, global leaders debate AI’s economic impact at Davos, and OpenAI signals the next wave of AI-focused hardware.
TensorTeach AI
January 27, 2026
This Week In AI
Over the past week, AI momentum stayed strong across government, enterprise, and global economic discussions, underscoring how deeply artificial intelligence is reshaping technology and policy. Leading the headlines, OpenAI partnered with government contractor Leidos to deploy generative and agentic AI capabilities across federal missions, signaling accelerated adoption of AI within public sector workflows. Meanwhile, industry conversations around autonomous agents and agent-driven AI remain central as companies and governments alike explore more sophisticated task-oriented AI systems.
On the global stage, AI dominated discussions at the World Economic Forum in Davos, where leaders highlighted both the promise of AI investment and the risks of labor disruption and geopolitical competition. In parallel, OpenAI confirmed plans for an AI-focused consumer hardware device slated for late 2026, a move that could broaden how people interact with AI outside of screens and keyboards.
Beyond headlines, recent analyses have flagged AI’s role in transforming forecasting and infrastructure—from improved weather predictions with AI models to debates over the sustainability of the AI infrastructure build-out—illustrating that foundational technology and its economic dynamics are rapidly evolving together.
This Week In AI Research
VideoThinker: Building Agentic VideoLLMs with LLM-Guided Tool Reasoning
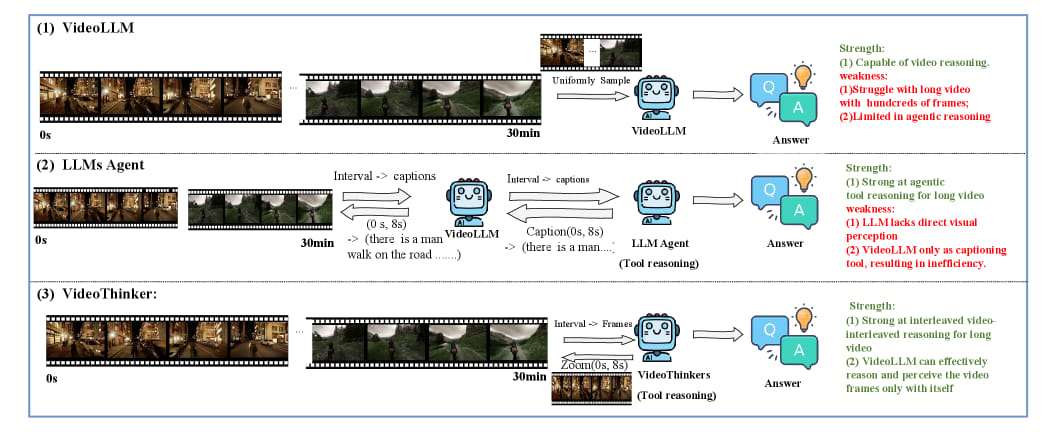
Image from arXiv paper.
What’s the research question?
How can agentic tools and synthetic data improve long-form video understanding in Video Large Language Models (VideoLLMs)?
What did the authors do?
The authors introduced VideoThinker, a novel approach to enhance VideoLLMs by integrating agentic tools and synthetic data generation:
Agentic tools: Two key tools were developed:
Temporal Retrieval: Identifies relevant video segments using semantic similarity with clip and subtitle retrieval.
Temporal Zoom: Allows detailed inspection of specific video intervals through Frame Zoom and Subtitle Zoom.
Textual captioning: Converts videos into rich textual descriptions to facilitate reasoning.
Tool-guided reasoning: An agentic LLM generates multi-step tool-use sequences in caption space, simulating how tools are applied over time.
Grounding to video: Replaces captions with actual video frames to create a large-scale interleaved video-tool reasoning dataset.
Fine-tuning: Uses this synthetic dataset to train the VideoLLM to actively retrieve and perceive key frames during reasoning.
Confidence-gated tool controller: Dynamically decides when to trigger multi-round tool-based reasoning based on confidence scores, balancing efficiency and accuracy.
What did they find?
VideoThinker achieved strong performance on several benchmarks, demonstrating the effectiveness of their approach:
Outperformed open-source models and was competitive with closed-source systems and LLM-based agents.
Benchmarks included:
54.8% on MLVU
48.9% on LVBench
53.7% on VideoMME
59.7% on LongVideoBench
Ablation studies showed that:
Increasing the number of sampled frames improved accuracy.
Adaptive confidence thresholds optimized the trade-off between efficiency and performance.
Why does this matter?
This work demonstrates that synthetic, tool-augmented training data can significantly enhance the ability of VideoLLMs to understand long-form videos. By enabling models to actively retrieve and reason over key video segments with adaptive tool use, VideoThinker advances the state of the art in cross-modal reasoning and long-video comprehension. This has broad implications for applications such as video summarization, content retrieval, and autonomous agents that need to interpret complex, lengthy visual narratives efficiently and accurately.
Key Points
Introduces VideoThinker, a VideoLLM that uses agentic tools for long-form video understanding.
Combines synthetic tool-interaction trajectories with caption-to-video grounding for training.
Employs adaptive confidence gating to balance reasoning accuracy and efficiency.
Achieves state-of-the-art results on multiple long-video benchmarks.
Dep-Search: Learning Dependency-Aware Reasoning Traces with Persistent Memory

Image from arXiv paper.
What’s the research question?
How can explicit modeling of dependencies between reasoning steps, combined with persistent memory, improve the multi-hop reasoning abilities of large language models (LLMs)?
What did the authors do?
The authors developed Dep-Search, a novel framework designed to enhance structured reasoning in LLMs through:
Dependency-aware decomposition: Using a QDMR-style approach, the model explicitly models dependencies between sub-questions, generating them in an order that respects their logical relationships.
Persistent memory system: Automatically stores summarized facts from reasoning searches, enabling efficient retrieval via embedding-based similarity search.
Joint training with reinforcement learning: Employs Generalized Relative Policy Optimization (GRPO) to optimize the entire search, reasoning, and memory pipeline simultaneously at the trajectory level.
Autonomous question decomposition and answer synthesis: During inference, the model decomposes complex questions, retrieves relevant information from memory, and synthesizes answers through reinforcement learning-guided search.
What did they find?
Dep-Search significantly outperformed baseline methods on six question-answering datasets, achieving:
Average scores of 39.29 and 49.77 on Qwen2.5-3B-Instruct and Qwen2.5-7B-Instruct models, respectively.
Notable improvements in multi-hop reasoning tasks, especially as model size increased (a 10.5-point gain from 3B to 7B models).
Ablation studies confirmed the importance of dependency-aware decomposition, persistent memory, and fact summarization.
Sensitivity analyses showed the approach is robust to hyperparameter choices.
Why does this matter?
Dep-Search advances the field of multi-hop reasoning by demonstrating that explicitly modeling dependencies between reasoning steps and integrating persistent memory can significantly improve the accuracy and efficiency of large language models. This structured approach enables models to better handle complex questions requiring multiple reasoning steps, which is critical for real-world applications like complex question answering, scientific reasoning, and decision support. Moreover, the use of reinforcement learning to jointly optimize search, reasoning, and memory components offers a promising direction for future research in structured reasoning and external knowledge integration, potentially leading to more intelligent and adaptable AI systems.
Key Points
Introduces dependency-aware structured reasoning using QDMR-style decomposition.
Employs a persistent memory system for efficient retrieval of summarized facts.
Uses reinforcement learning (GRPO) to jointly optimize search, reasoning, and memory.
Achieves state-of-the-art results on multiple multi-hop reasoning benchmarks, especially in larger models.
Code over Words: Overcoming Semantic Inertia via Code-Grounded Reasoning

Image from arXiv paper.
What’s the research question?
How can large language models overcome semantic inertia and improve reasoning in environments with mutable ontologies?
What did the authors do?
The authors introduced a novel framework called Code-Grounded Vistas (LCV) that enables language models to better handle environments where rules and concepts change dynamically. Their approach involves:
Representing environment rules as executable Python code rather than natural language descriptions, allowing for precise and flexible rule manipulation.
Using amortized theory induction and counterfactual contrastive alignment to train models to generate code that accurately reflects current environment states.
Training the model on paired examples with identical states but contradictory rules, forcing it to produce different code outputs for the same visual input depending on the rules.
During inference, synthesizing a Python transition kernel in a single pass, which is then used by a classical planner to decide actions.
Evaluating the framework in the Baba Is You environment, a game where physical laws are mutable text rules, measuring the model’s ability to adapt to changing rules across increasing levels of semantic dissonance.
What did they find?
The LCV framework demonstrated significant advantages over inference-heavy baselines like TheoryCoder:
Achieved success rates of 75.56% in Tier 2 and 62.00% in Tier 3, outperforming baselines in robustness and efficiency.
Showed strong systematic generalization by maintaining performance across spatial and logical variations in the environment.
Reduced inference latency by a factor of 4 compared to search-based methods, enabling faster decision-making.
Effectively inhibited prior biases and adapted to rule changes, overcoming the challenge of semantic inertia where previous knowledge interferes with new reasoning.
Why does this matter?
This work challenges the common assumption that larger models are always better for reasoning tasks. Instead, it highlights the importance of representational alignment and explicit state tracking in environments where rules and concepts are constantly changing. By representing rules as executable code, the approach provides a scalable and efficient way to overcome semantic inertia, which is crucial for real-time decision-making in dynamic settings. Applications include robotics, game AI, and any domain requiring adaptive reasoning over mutable ontologies, paving the way for more flexible and robust intelligent agents.
Key Points
Introduces Code-Grounded Vistas (LCV), a framework for reasoning with mutable environment rules.
Represents rules as executable Python code to improve flexibility and inhibition of prior biases.
Outperforms inference-heavy baselines in success rate and efficiency in the Baba Is You environment.
Enables systematic generalization across spatial and logical variations.