- TensorTeach's Newsletter
- Posts
- OpenAI, Google, Microsoft at India AI Summit as Apple Delays AI Siri — Global AI Governance, Chip Demand, and Workforce Impact Rise
OpenAI, Google, Microsoft at India AI Summit as Apple Delays AI Siri — Global AI Governance, Chip Demand, and Workforce Impact Rise
From the India AI Impact Summit 2026 and proposed Delhi Declaration on AI to Apple’s delayed assistant and surging memory-chip demand, this week’s news shows AI moving from research labs into global infrastructure—bringing regulation, safety, and job disruption to the forefront.
TensorTeach AI
February 17, 2026
This Week In AI
Over the past week, major AI developments centered on global AI governance, big-tech strategy shifts, workforce disruption, infrastructure constraints, and ongoing safety concerns.
At the policy level, the India AI Impact Summit 2026 brought together leaders from OpenAI, Google, Microsoft, and other major labs in one of the first large-scale AI summits hosted in the Global South. The summit aims to produce a “Delhi Declaration” on AI, focused on responsible regulation, multilingual AI deployment, and real-world AI applications like robotics and translation systems. These discussions signal a shift from abstract safety debates toward practical governance for AI systems already entering global markets.
On the product side, Apple delayed its long-anticipated AI-powered Siri upgrade again, highlighting how difficult it remains to build reliable agent-level assistants. Even trillion-dollar companies are struggling with real-world deployment of autonomous AI systems, suggesting that core breakthroughs in reasoning, planning, and tool use are still unsolved research problems.
Meanwhile, reports highlighted growing worker anxiety as AI adoption accelerates across software development and knowledge work. Companies are pushing productivity expectations higher as AI tools spread, reinforcing demand for AI education and upskilling across industries.
Infrastructure pressures also stayed visible. Demand for high-bandwidth memory chips surged as AI labs scale training clusters, while concerns about AI spending drove volatility in tech stocks. This reflects a familiar pattern from past technology booms: massive infrastructure investment before clear winners emerge.
Finally, new safety reports released ahead of the summit warned about misuse risks, technical failures, and systemic impacts of increasingly powerful models, underscoring the need for alignment research and governance alongside rapid deployment.
This Week In AI Research
MATEO: A Multimodal Benchmark for Temporal Reasoning and Planning in LVLMs
What’s the research question?
How well can Large Vision Language Models (LVLMs) understand and reason about the temporal execution order (TEO) of steps in multimodal tasks?
What did the authors do?
The authors developed MATEO, a new benchmark to evaluate LVLMs' ability to grasp the sequence of actions in multimodal contexts:
Dataset creation: Compiled 300 high-quality Italian recipes, each with step-by-step instructions paired with images.
Annotation: Used crowdsourcing to create TEO graphs that capture dependencies among recipe steps, representing the correct temporal order.
Model evaluation: Tested six LVLMs using various prompting strategies:
Zero-shot (no examples)
In-context learning (ICL) with examples
Chain of thought (CoT) prompting to encourage reasoning
Self-reflection prompting for model introspection
Fine-tuning: Fine-tuned the best model, InternVL3.5-8B, using LoRA (a parameter-efficient fine-tuning method).
Assessment metric: Accuracy based on whether models correctly identified the original step order versus swapped orders, testing their understanding of temporal relations.
What did they find?
The study revealed several key insights:
Limited zero-shot performance: Models performed poorly without any prompting, with accuracy near zero.
Prompting strategies help but vary: Adding instructions, ICL, or CoT improved results, but gains depended on the model. Qwen2.5-VL-72B achieved the highest accuracy of 0.68 with ICL.
Fine-tuning boosts accuracy: Fine-tuning InternVL3.5-8B increased accuracy to 0.69.
Difficulty with reversed order: Models struggled when the temporal order was reversed, indicating challenges in reasoning about step dependencies.
Best performance with self-reflection: GPT-5.1 reached 0.74 accuracy using self-reflection prompts and multimodal inputs.
What does this matter?
MATEO provides a critical benchmark for evaluating how well LVLMs can understand and reason about the sequence of actions in multimodal tasks, which is essential for applications like cooking assistants, instructional robots, and complex planning systems. The findings highlight that current LVLMs have significant limitations in temporal reasoning, especially when steps are reordered or dependencies are complex. By exposing these weaknesses, MATEO guides future research toward developing more sophisticated multimodal reasoning models that can better integrate visual and textual information over time. This work advances the goal of creating AI systems capable of understanding real-world activities in a human-like, context-aware manner.
Key Points
Introduces MATEO, a multimodal benchmark with recipes and TEO annotations to evaluate temporal reasoning in LVLMs.
Shows that current LVLMs struggle with understanding step dependencies, especially under reversed order conditions.
Demonstrates that prompting strategies and fine-tuning can improve model performance but do not fully solve the challenge.
Highlights the need for more advanced multimodal temporal reasoning capabilities in future AI systems.
TikArt: Aperture-Guided Observation for Fine-Grained Visual Reasoning via Reinforcement Learning
What’s the research question?
How can we improve fine-grained visual reasoning in multimodal large language models (MLLMs) by enabling active visual exploration and explicit grounding?
What did the authors do?
The authors developed TikArt, a novel approach that combines language reasoning with active visual exploration through a reinforcement learning framework. Key components include:
Think-Aperture-Observe (TAO) loop: The model alternates between reasoning in language and inspecting specific image regions.
Aperture actions: The model chooses regions of interest using two methods: Zoom (rectangular crops) and Segmentation (mask-based crops).
Explicit observations: After each aperture, the model generates a natural-language description of the visual content, which is added to the language context.
Reinforcement learning optimization: The policy is trained using AGRPO, encouraging effective aperture selection and task success, with a reward combining correct answers and purposeful exploration.
Evaluation variants: A prompt-only version applies the aperture prompts at inference without fine-tuning.
What did they find?
TikArt demonstrated strong improvements over baseline models and state-of-the-art competitors:
Achieved +15 and +8 points improvements on high-resolution benchmarks V* and HR-Bench-8K, respectively.
Approached or surpassed larger models like Qwen3-VL-32B (32B parameters) and 235B-parameter models.
Matched or outperformed proprietary systems such as GPT-5 and Gemini-2.5 on 8K image settings.
Narrowed the gap to GPT-4o and Gemini-2.5 on real-world benchmarks (MME-RealWorld-Lite and MMStar), especially on local visual cues.
Top scores on ReasonSeg, demonstrating effective pixel-level grounding of visual details.
Ablation studies confirmed the importance of the explicit Observation phase; removing it led to unstable training and reduced performance.
Why does this matter?
TikArt introduces a new active perception paradigm for multimodal reasoning, moving beyond static global image encodings to human-like visual exploration. Its explicit grounding and interpretable aperture trajectories enable more autonomous and precise multimodal agents, with broad potential applications in robotics, assistive AI, and scientific discovery. By actively seeking and describing critical visual details, TikArt enhances the ability of large language models to understand complex visual scenes and answer fine-grained questions, paving the way for more intelligent and interactive AI systems.
Key Points
Introduces a Think-Aperture-Observe loop combining language reasoning with active visual exploration.
Uses reinforcement learning to optimize aperture selection and task performance.
Achieves state-of-the-art results on high-resolution visual reasoning benchmarks.
Provides explicit, natural-language descriptions of visual regions to improve interpretability and grounding.
Broken Chains: The Cost of Incomplete Reasoning in LLMs
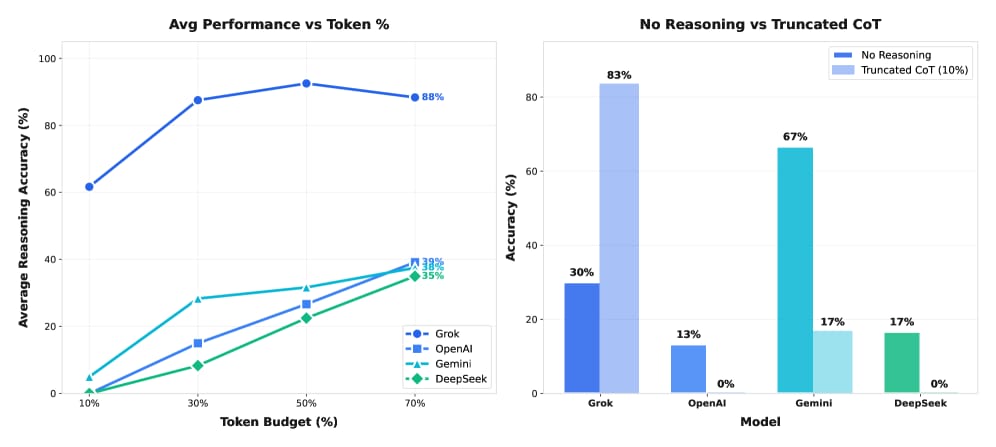
Image from arXiv paper.
What’s the research question?
How do different reasoning modalities (code, natural language comments, hybrid of both, or none) perform under token constraints in large language models (LLMs)?
What did the authors do?
The authors systematically evaluated four large language models—GPT-5.1, Gemini 3 Flash, DeepSeek-V3.2, and Grok 4.1—on three mathematical reasoning benchmarks (GSM8K, AIME, HMMT). They tested five reasoning conditions:
Code-only: reasoning using generated code
Comments-only: reasoning using natural language comments
Hybrid: combining code and comments
Nothing: no explicit reasoning, direct answer
Standard chain-of-thought (CoT): traditional step-by-step reasoning
They constrained token budgets to 10%, 30%, 50%, and 70% of the optimal reasoning length to simulate resource limitations. Success was measured by the fraction of problems correctly answered, either by code output or direct answer extraction. This controlled setup allowed the authors to isolate the effects of reasoning modality and token constraints on model performance.
What did they find?
Key results include:
DeepSeek-V3.2 achieved 53% success with no reasoning but dropped sharply to 17% when using truncated chain-of-thought (CoT) at 50% token budget, indicating high sensitivity to token constraints.
Gemini 3 Flash maintained 43-47% success using code reasoning even at 30-50% token budgets, showing robustness of code-based reasoning under constraints.
Hybrid reasoning (code + comments) underperformed compared to single modalities, suggesting that combining modalities does not necessarily improve robustness.
Grok 4.1 was highly resilient, maintaining 80-90% success at 30% token budget, while OpenAI and DeepSeek models collapsed to 7-27%, highlighting significant variability across models.
The study demonstrated that incomplete reasoning chains actively mislead models, emphasizing that more explicit reasoning does not always equate to better performance, especially under resource limitations.
Limitations include the focus on mathematical benchmarks and the specific models tested; results may vary with other tasks or architectures.
Why does this matter?
This work challenges the common assumption that explicit, detailed reasoning always improves model performance. It shows that the robustness of reasoning modalities—how well they perform under constraints—is crucial for deploying AI systems in real-world scenarios where computational resources and token budgets are limited. By providing a framework to evaluate and compare reasoning strategies under constraints, the study informs the design of more resilient and efficient AI systems. This has broad implications for applications requiring reliable reasoning, such as automated tutoring, complex problem-solving, and interactive agents operating in dynamic environments.
Key Points
Explicit reasoning methods like code and comments vary greatly in robustness under token constraints.
Incomplete reasoning chains can actively mislead large language models, reducing accuracy.
Model performance under resource limits depends heavily on the reasoning modality and model architecture.
The study provides a framework for evaluating reasoning robustness to guide future AI system design.