- TensorTeach's Newsletter
- Posts
- OpenAI Expands Into Healthcare With ChatGPT Health as Anthropic Scales Up, Super Bowl LX Ad Returns, and DeepMind Powers Boston Dynamics Robots
OpenAI Expands Into Healthcare With ChatGPT Health as Anthropic Scales Up, Super Bowl LX Ad Returns, and DeepMind Powers Boston Dynamics Robots
ChatGPT Health and OpenAI for Healthcare expand into medicine, Anthropic scales life sciences, OpenAI eyes a Super Bowl LX ad, and DeepMind powers Boston Dynamics’ Atlas.
TensorTeach AI
January 13, 2026
This Week In AI
OpenAI made one of its clearest moves yet into healthcare with the launch of ChatGPT Health and the broader push for OpenAI for Healthcare, signaling a future where AI isn’t just a tool for productivity, but something people may increasingly treat as a front-line resource for life decisions. Anthropic echoed that trend, accelerating its own healthcare/life-sciences positioning while also fueling the ongoing arms race with major funding and scaling signals.
OpenAI is reportedly planning to return to the Super Bowl with another 60-second ad during NBC’s broadcast of Super Bowl LX. The report frames this as a continuation of OpenAI’s push to market ChatGPT directly to a mass consumer audience, following its Super Bowl presence last year.
Separately, Boston Dynamics announced a partnership with Google DeepMind focused on bringing DeepMind’s Gemini Robotics foundation models into Boston Dynamics’ robotics work. The collaboration is tied to improving robot intelligence and learning capability, and it includes Boston Dynamics’ humanoid program (such as Atlas) as part of the effort.
This Week In AI Research
Plasticity vs. Rigidity: The Impact of Low-Rank Adapters on Reasoning on a Micro-Budget

Image from arXiv paper.
What’s the research question?
Can small language models develop strong reasoning capabilities under extreme computational constraints using low-rank adapters and reinforcement learning?
What did the authors do?
The authors investigated how different adapter capacities affect reasoning in small language models by:
Using a diverse set of small language models (≤1.5B parameters) trained on a single GPU with a 24-hour limit.
Applying Low-Rank Adaptation (LoRA) to fine-tune models, varying the rank (r) from 8 to 256 to control adaptation capacity.
Training models with Reinforcement Learning with Verifiable Rewards (RLVR) using Group Relative Policy Optimization (GRPO), combining format adherence and correctness as rewards.
Limiting response length to encourage detailed reasoning and conducting 300 update steps during training.
Evaluating on benchmarks including MATH500 (validation) and AIME24/25, AMC23 (final testing).
What did they find?
Key results include:
High-rank adapters (r=256) enabled models to better optimize rewards and improve reasoning, elongating reasoning chains and achieving higher benchmark scores (e.g., 40.0% Pass@1 on AIME24).
Low-rank adapters (r=8) were less effective, showing limited reasoning improvements.
Heavily math-oriented models (Qwen2.5-Math-1.5B, Qwen3-0.6B) experienced performance collapse at high ranks, likely due to destructive interference from noisy updates.
Response length correlated with reasoning performance, with more plastic models expanding their reasoning chains.
DeepScaleR-1.5B outperformed others, reaching 70.0% Pass@16 in final evaluation.
Why does this matter?
This work demonstrates that small language models can develop advanced reasoning skills even under severe compute constraints by leveraging high-capacity (high-rank) adapters combined with reinforcement learning. It highlights the importance of adapter capacity and initialization in fostering model plasticity—the ability to adapt and learn complex behaviors. The findings suggest that high-rank LoRA adapters can unlock latent reasoning abilities in resource-efficient ways, offering a cost-effective alternative to full-parameter fine-tuning. This has broad implications for deploying intelligent systems in environments with limited hardware, enabling smarter agents and reasoning tools without the need for massive models or extensive compute resources. It also guides future research on designing adaptable, high-capacity adapters tailored for small models aiming to perform complex reasoning tasks.
Key Points
High-rank LoRA adapters significantly improve reasoning in small language models under tight computational budgets.
Adapter capacity (rank) influences model plasticity and ability to develop complex reasoning chains.
Reinforcement learning with verifiable rewards effectively trains small models to reason and follow formats.
Heavily math-focused models can suffer from high-rank adaptation due to noisy updates, highlighting the need for careful tuning.
LLMTrack: Semantic Multi-Object Tracking with Multimodal Large Models
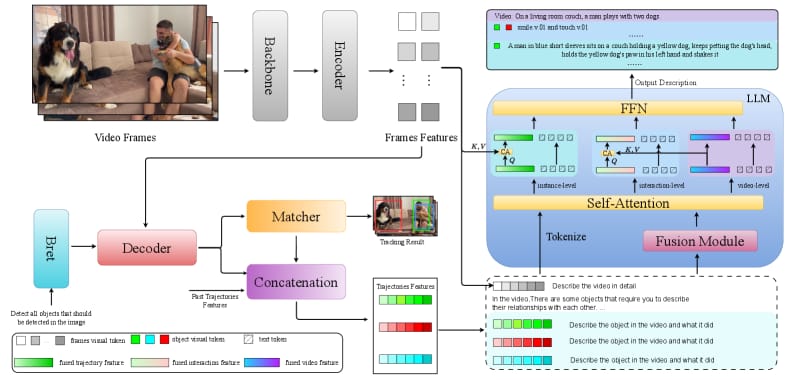
Image from arXiv paper.
What’s the research question?
How can we integrate semantic understanding into multi-object tracking systems to improve their interpretability and reasoning capabilities?
What did the authors do?
The authors introduced LLMTrack, a novel framework that combines large multimodal models with specialized fusion modules and progressive training strategies to enhance multi-object tracking (MOT) with semantic reasoning:
Decoupled architecture: Separates perception and reasoning into two modules: a perception frontend (Grounding DINO) for generating instance embeddings from video frames, and a reasoning backend (LLaVA-OneVision) for processing these embeddings into natural language descriptions.
Spatio-Temporal Fusion Module: Aggregates interaction features between objects and contextual video information, enabling the model to understand complex trajectories and interactions over time.
Three-stage training: (1) Visual-Semantic Alignment to connect visual features with text, (2) Temporal Association to maintain object identities across frames, and (3) Semantic Injection to fine-tune the language model for structured description generation.
Inference outputs: Generates both detailed object trajectories and semantic descriptions of behaviors and interactions, supporting tasks like scene summarization and interaction recognition.
What did they find?
LLMTrack demonstrated strong performance improvements:
Achieved a HOTA score of 74.61% on the BenSMOT benchmark, surpassing previous state-of-the-art methods like SMOTer (71.98%).
Produced high-quality semantic outputs with a Video CIDEr score of 0.462 and an Interaction F1 score of 0.526, indicating accurate description of object behaviors and interactions.
Ablation studies confirmed that combining Instance Fusion and Video Fusion modules led to the best results, highlighting the importance of integrating object-level and scene-level information.
Limitations include increased computational complexity due to multimodal processing and the need for extensive training data to align visual and semantic features effectively.
Why does this matter?
By integrating semantic reasoning directly into multi-object tracking, LLMTrack moves beyond traditional geometric-based methods to produce interpretable, language-rich descriptions of dynamic scenes. This advancement has significant implications:
Enhanced interpretability: Enables systems to explain object behaviors and interactions in natural language, making outputs more accessible to humans.
Improved downstream tasks: Facilitates scene understanding, interaction recognition, and video summarization, which are valuable in surveillance, autonomous driving, and robotics.
Bridging perception and language: Demonstrates a promising approach to unify vision and language models for complex reasoning in dynamic environments.
Key Points
Combines perception (Grounding DINO) and reasoning (LLaVA-OneVision) in a decoupled, multimodal framework.
Uses a Spatio-Temporal Fusion Module to capture object interactions and scene context over time.
Trains in three stages to align visual features with text, maintain object identities, and generate semantic descriptions.
Outperforms previous MOT methods on benchmark metrics and provides rich semantic outputs.
Thinking with Deltas: Incentivizing Reinforcement Learning via Differential Visual Reasoning Policy

Image from arXiv paper.
What’s the research question?
How can reinforcement learning policies be improved to better integrate visual perception with reasoning in multimodal domains?
What did the authors do?
The authors introduced a novel reinforcement learning framework called Differential Visual Reasoning Policy (DVRP) that enhances how AI agents understand and reason about visual inputs by explicitly aligning perception with reasoning through intrinsic visual supervision.
Constructed three visual views for each training instance: Invariant (original image), Decremental (masked visual input), and Incremental (perturbed visual input).
Designed a unified training objective that balances task performance with intrinsic visual grounding by:
Maximizing divergence between Invariant and Decremental views to encourage visual sensitivity.
Minimizing divergence between Invariant and Incremental views to promote visual robustness.
Implemented a Sigmoid decay schedule to dynamically anneal diffusion noise, balancing structural robustness and convergence stability during training.
Trained the policy using reinforcement learning with a reward function based on task accuracy and the intrinsic visual constraints.
Evaluated DVRP on challenging general mathematical reasoning and medical diagnostic tasks, comparing against baselines like GRPO and DAPO.
What did they find?
DVRP achieved state-of-the-art performance on both general and domain-specific benchmarks:
69.7% accuracy on a 7B parameter model.
62.7% accuracy on a 3B parameter model.
Significant improvements over baselines: +40.5% relative gain over GRPO and +28.4% over DAPO in medical tasks.
Ablation studies confirmed that both visual sensitivity and visual robustness components contributed to the performance gains.
Qualitative analyses showed improved visual grounding and reduced hallucinations, indicating more reliable reasoning about visual inputs.
Why does this matter?
This work addresses a key challenge in multimodal reinforcement learning: the perception-reasoning decoupling. By explicitly aligning visual perception with reasoning through intrinsic supervision, DVRP enhances visual grounding and robustness without relying on external annotations. This scalable approach can lead to more trustworthy and interpretable multimodal AI systems capable of complex reasoning in diverse domains, from mathematics to medicine. Its success suggests broad applicability for improving how AI agents understand and reason about visual information in real-world settings.
Key Points
Introduces DVRP, a reinforcement learning framework with intrinsic visual supervision via differential policies.
Constructs invariant, decremental, and incremental visual views to balance sensitivity and robustness.
Achieves state-of-the-art results on mathematical and medical reasoning benchmarks.
Enhances visual grounding and reduces hallucinations in multimodal AI agents.