- TensorTeach's Newsletter
- Posts
- New York Regulates AI Companions as Amazon Reorganizes, Meta Builds New Models, and ServiceNow Makes a $7.75B Security Bet
New York Regulates AI Companions as Amazon Reorganizes, Meta Builds New Models, and ServiceNow Makes a $7.75B Security Bet
State-level AI safety laws meet major strategic shifts from Amazon, Meta, and ServiceNow in a consequential week for artificial intelligence.
TensorTeach AI
December 23, 2025
This Week In AI
AI is quietly crossing a threshold this week—not with a single breakthrough model, but with a series of moves that signal how seriously governments and companies are beginning to treat its real-world impact.
In the U.S., lawmakers are stepping in where norms haven’t yet formed. New legislation in AI companions in New York and California now targets chatbots designed to simulate social or emotional relationships, mandating safety and transparency features, with a particular focus on youth protections and crisis response. New York has gone further, signing broader AI safety legislation that introduces incident reporting and governance requirements for advanced models—potentially laying the groundwork for a state-level regulatory template others may soon follow.
At the same time, Big Tech is reorganizing for the long game. Amazon reorganized its AI leadership, unifying AGI research and custom chip development under a single executive, a move that underscores how tightly coupled software intelligence and hardware advantage have become. Meta is developing new AI models, reportedly building systems for image and video generation alongside specialized models for code tasks, signaling a shift toward more domain-specific intelligence as its AI research unit scales.
Enterprise AI is consolidating fast. ServiceNow’s $7.75B acquisition of Armis highlights how AI-driven cybersecurity is becoming one of the most valuable—and defensible—applications of artificial intelligence, as enterprises race to secure increasingly automated systems.
This Week In AI Research
M3-Verse: A “Spot the Difference” Challenge for Large Multimodal Models
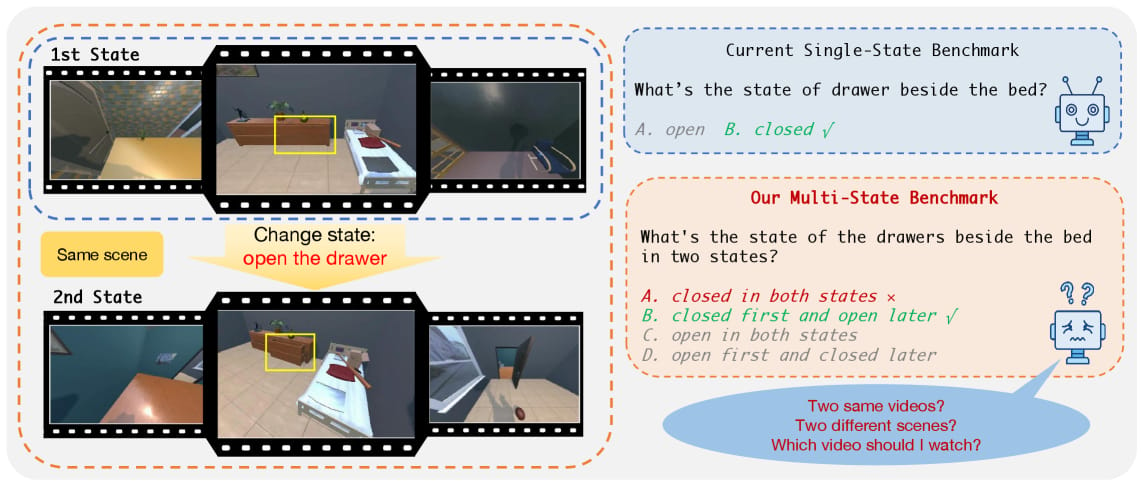
Image from arXiv paper.
What’s the research question?
How well do large multimodal models (LMMs) understand and reason about state transitions in paired videos of indoor scenes?
What did the authors do?
The authors introducedM3-Verse, a new benchmark designed to evaluate LMMs’ ability to perceive and reason about changes between two related videos of indoor environments. Their approach included:
Creating a dataset of 270 paired egocentric videos capturing indoor scenes before and after a state change (e.g., object moved or attribute changed).
Generating 2,932 questions that require models to identify differences, localize objects, and reason about scene attributes, categorized into intra-state (single scene) and inter-state (comparison) questions.
Using an automated, template-based pipeline to produce high-quality question-answer pairs grounded in rich scene metadata and hierarchical object/room references.
Applying a two-stage filtering process, combining text-based and multimodal checks, followed by human review to ensure question clarity and relevance.
What did they find?
Key results include:
All evaluated LMMs performed poorly on M3-Verse, with accuracy scores between 30% and 45%, compared to humans who scored around 90%.
Larger models did not consistently outperform smaller ones, indicating that scale alone does not solve the reasoning challenge.
Models with vision input outperformed vision-blind LLMs, highlighting the importance of visual perception.
Many models excelled at inter-state questions that involved comparing two scenes but struggled with intra-state questions requiring precise localization of scene elements.
Introducing Hierarchical Captioning and Text-based Reasoning (HCTR) significantly boosted model performance, especially on inter-state tasks, by translating visual differences into text-based reasoning problems.
Why does this matter?
M3-Verse exposes critical limitations in current large multimodal models’ ability to perceive and reason about dynamic scene changes. By providing a challenging benchmark that combines spatial, temporal, and attribute reasoning, it pushes the development of models that can better integrate visual and semantic information. Improvements in this area are vital for advancing AI applications that require understanding of real-world environments, such as robotics, autonomous systems, and assistive technologies. Enhancing models’ capacity to detect and interpret scene changes can lead to more adaptable, intelligent agents capable of operating effectively in complex, dynamic settings.
Key Points
M3-Verse is a new benchmark testing large multimodal models’ reasoning about scene changes in paired videos.
Models perform poorly compared to humans, highlighting significant challenges.
Visual input improves model performance over text-only models, but reasoning about local details remains difficult.
Hierarchical Captioning and Text-based Reasoning methods help bridge the gap by translating visual differences into text reasoning tasks.
CrashChat: A Multimodal Large Language Model for Multitask Traffic Crash Video Analysis
What’s the research question?
How can a multimodal large language model be designed and trained to perform comprehensive traffic crash video analysis across multiple tasks?
What did the authors do?
The authors developed CrashChat, a multimodal large language model (MLLM) built on the VideoLLaMA3 framework, tailored for traffic crash video analysis. Their approach included:
Using a vision encoder to convert input crash videos into a sequence of video token embeddings.
Applying a text tokenizer to convert input questions into text tokens.
Mapping both video and text tokens into a shared embedding space via cross-modal projection modules.
Fine-tuning the model on traffic crash datasets using Low-Rank Adaptation (LoRA), which introduces learnable low-rank matrices to adapt the model efficiently without overfitting.
Dividing the training tasks into two groups: linguistic-centric tasks (crash recognition, description, causal and prevention reasoning) and perception-centric tasks (crash localization, pre-crash localization).
Optimizing each task group separately to prevent negative transfer, while also using perception tasks as auxiliary objectives during linguistic task training to promote cross-task knowledge transfer.
Implementing separate LoRA modules for each task group to enable specialized adaptation while maintaining shared representations.
What did they find?
CrashChat achieved remarkable results across six core crash video analysis tasks:
Near-perfect accuracy in crash recognition.
A 176% improvement in crash localization compared to previous methods.
A 40% improvement in pre-crash localization.
Textual task improvements, with BLEU scores increasing by 0.18-0.41 and ROUGE scores by 0.18-0.42 over general multimodal large language models.
Ablation studies confirmed that the combination of task decoupling and heterogeneous multitask learning significantly contributed to these performance gains.
Limitations include the focus on traffic crash videos, which may limit generalizability to other domains, and the reliance on high-quality domain-specific datasets for fine-tuning.
Why does this matter?
CrashChat represents a significant advancement in applying multimodal large language models to real-world safety-critical tasks. By effectively integrating visual and textual data and carefully managing multiple related tasks, it sets a new standard for traffic crash analysis, which can inform better accident prevention and response strategies. Moreover, the innovative training strategies—such as task decoupling and domain-specific fine-tuning—offer a blueprint for tackling complex multimodal problems in other fields like autonomous driving, medical diagnostics, and robotics. This work highlights the potential of combining domain knowledge with advanced multimodal learning to address real-world challenges more effectively.
Key Points
CrashChat is a multimodal large language model tailored for traffic crash video analysis, integrating vision and language modalities.
Uses a dual-task training strategy with separate optimization for perception and linguistic tasks to improve multitask performance.
Achieved state-of-the-art results in crash recognition, localization, and reasoning tasks, outperforming general MLLMs.
Demonstrates effective domain adaptation and multitask learning strategies that can be applied to other complex multimodal problems.
SafeMed-R1: Adversarial Reinforcement Learning for Generalizable and Robust Medical Vision–Language Reasoning

Image from arXiv paper.
What’s the research question?
How can we improve the robustness and reasoning quality of vision-language models for medical visual question answering (VQA)?
What did the authors do?
The authors developed SafeMed-R1, a novel framework that combines adversarial training, reinforcement learning, and structured reasoning to enhance medical VQA models:
Two-stage training process: Stage 1: Supervised Fine-Tuning (SFT) on expert-annotated data using maximum likelihood estimation.
Stage 2: Group Relative Policy Optimization (GRPO), a reinforcement learning algorithm that explicitly optimizes the quality of reasoning traces (chains of thought) and final answers.
Structured output: The model generates a reasoning chain (T) and a final answer (A), with an external reward model (Rϕ) assessing the coherence and clinical soundness of T.
Robustness enhancements: Adversarial training (AT) is integrated into both stages:
Stage 1: PGD-based adversarial perturbations on input images during fine-tuning (AT-SFT).
Stage 2: Adversarial examples generated by minimizing expected reward (AT-GRPO).
Parameter efficiency: Low-rank adaptation (LoRA) used for training efficiency.
Inference robustness: Randomized Smoothing (RS) adds Gaussian noise to inputs, providing probabilistic robustness guarantees.
What did they find?
The SafeMed-R1 framework achieved significant improvements in robustness and accuracy:
On the OmniMedVQA benchmark (88,995 samples across 8 modalities), the model with reasoning traces (Think variant) achieved 84.45% accuracy under PGD adversarial attacks, a 59 percentage point improvement over standard fine-tuning (25.43%).
The reasoning-based model outperformed the direct-answer (Instruct) variant under attack (84.45% vs. 82.27%).
Under clean conditions, the Instruct model achieved 95.43% accuracy, while the Think model achieved 94.25%, showing minimal trade-off between robustness and clean accuracy.
The explicit reasoning trace improved interpretability and robustness, likely by providing a structured intermediate representation.
Limitations include the complexity of training and potential domain-specific tuning required for different medical tasks.
Why does this matter?
This work demonstrates that combining structured reasoning with adversarial training and certified defenses can produce medical vision-language models that are both highly accurate and resilient to adversarial attacks. This is crucial for healthcare applications, where AI errors can have serious consequences. The approach enhances trustworthiness by making model decisions more interpretable and robust. Moreover, the modular design of SafeMed-R1 allows it to be adapted to other high-stakes domains requiring reliable AI, such as legal or financial decision-making.
Key Points
Integrates adversarial reinforcement learning with structured reasoning for medical VQA.
Achieves large robustness gains against adversarial attacks while maintaining high accuracy.
Generates interpretable reasoning chains that improve model transparency.
Offers a scalable framework adaptable to other sensitive AI applications.