- TensorTeach's Newsletter
- Posts
- Meta, Nvidia, and SoftBank Accelerate the AI Race as Agents, Models, and Infrastructure Converge
Meta, Nvidia, and SoftBank Accelerate the AI Race as Agents, Models, and Infrastructure Converge
From Meta’s Manus acquisition and Nvidia’s talks with AI21 Labs to SoftBank’s $4B infrastructure bet, the past week shows how Big Tech is consolidating power across the full AI stack
TensorTeach AI
December 30, 2025
This Week In AI
Over the past week, momentum in AI continued to build as major players used acquisitions to accelerate their strategies. Meta Platforms agreed to acquire Manus for more than $2 billion, adding autonomous agent technology capable of planning and executing multi-step tasks. The deal underscores Meta’s focus on moving beyond chatbots toward AI systems that can act independently across products and workflows.
At the same time, Nvidia is reportedly in advanced talks to acquire AI21 Labs for $2–$3 billion. If completed, the acquisition would deepen Nvidia’s role in foundational AI model development, signaling a strategic shift from being primarily an infrastructure provider to owning more of the software and research layer that sits on top of its hardware dominance.
AI infrastructure also emerged as a key battleground. SoftBank Group announced plans to acquire DigitalBridge for roughly $4 billion, reflecting growing recognition that data centers, fiber networks, and connectivity are essential to scaling AI. In parallel, China released draft rules targeting human-like AI systems, highlighting how increased investment and capability are being matched by tighter regulatory scrutiny as AI becomes more autonomous and socially embedded.
This Week In AI Research
Self-Rewarded Multimodal Coherent Reasoning Across Diverse Visual Domains
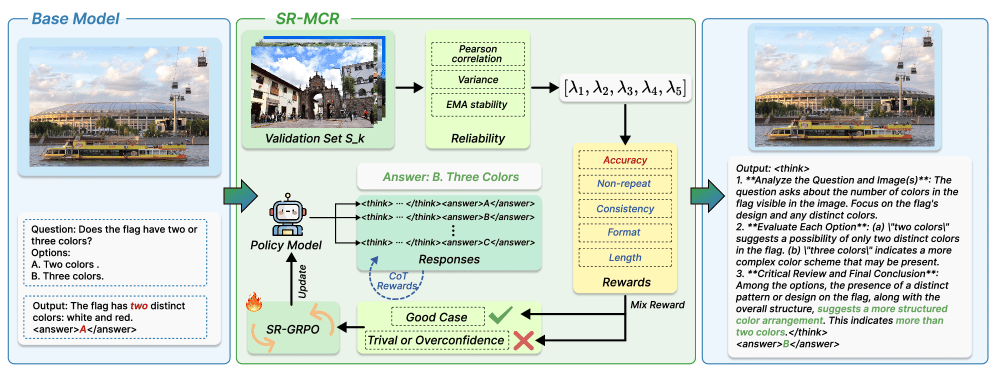
Image from arXiv paper.
What’s the research question?
Can intrinsic process signals derived directly from model outputs serve as a unified self-reward for training and diagnosing multimodal language models?
What did the authors do?
The authors developed a novel training framework called Self-Rewarded Multimodal Coherent Reasoning (SR-MCR) that enables models to learn and reason across diverse visual and textual inputs without relying on external labels. Key components include:
Unified self-reward: Combines five process-level signals—semantic alignment, lexical fidelity, non-redundancy, visual grounding, and step coherence—into a single normalized reward score.
Adaptive reliability weighting: Assigns weights to each signal based on their reliability, derived from correlation with validation accuracy, to improve robustness.
Critic-free GRPO objective with cooling regularization: Uses a gradient-based policy optimization that encourages high-reward responses while preventing overconfidence and trivial solutions.
Given an image, text prompt, and model outputs (final answer and reasoning trace), the model computes these five signals, combines them into a self-reward, and updates its parameters to generate more coherent and accurate multimodal reasoning.
What did they find?
The SR-MCR-7B model, with 7 billion parameters, achieved an average accuracy of 81.4% across multiple benchmarks, outperforming comparable models. Notably:
On the V*Bench dataset, it set new state-of-the-art results with an overall score of 80.63, excelling in attribute and spatial reasoning tasks.
Human evaluations showed the model's reasoning was preferred over baselines 90.82% of the time, indicating high reasoning quality.
Ablation studies confirmed that each of the five intrinsic signals and the cooling regularization contributed significantly to performance gains.
The framework demonstrated strong generalization across different model architectures and robustness against noisy reward signals, improving performance by 3.0–3.4% on internal benchmarks.
Limitations include potential computational overhead from generating multiple responses and the need to validate the approach across even more diverse modalities and tasks.
Why does this matter?
This work introduces a novel, label-free, process-aware self-reward mechanism for multimodal reasoning models, addressing key challenges in aligning and reasoning across vision and language. By leveraging intrinsic signals directly from model outputs, SR-MCR enables models to learn more coherent, visually grounded reasoning without relying on costly external annotations. Its robustness and generality make it a promising foundation for future research in self-supervised multimodal alignment, reasoning, and the development of more autonomous AI agents capable of complex cross-modal understanding. This advancement could accelerate progress in applications like visual question answering, robotics, and interactive AI systems that require integrated perception and reasoning.
Key Points
Introduces SR-MCR, a self-rewarded framework combining five intrinsic process signals for multimodal reasoning.
Achieves state-of-the-art accuracy and reasoning quality on diverse visual-language benchmarks.
Operates without external labels, relying solely on model-intrinsic signals and adaptive reliability weighting.
Demonstrates strong generalization and robustness across architectures and noisy reward signals.
Benchmark Success, Clinical Failure: When Reinforcement Learning Optimizes for Benchmarks, Not Patients
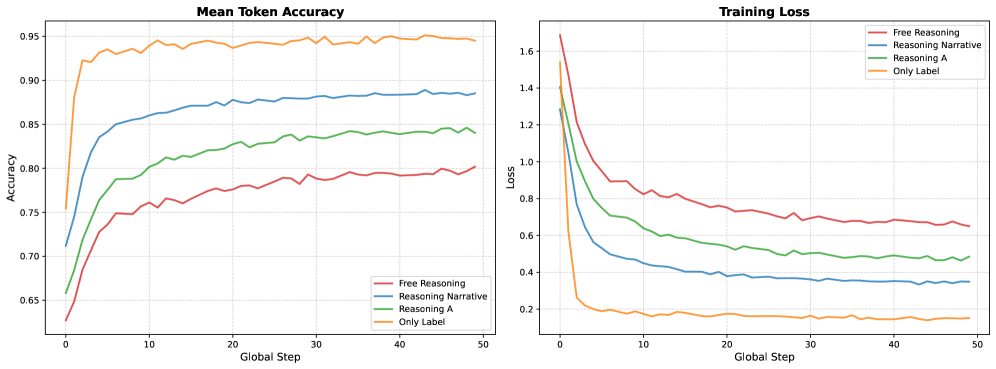
Image from arXiv paper.
What’s the research question?
Can reinforcement learning (RL) training strategies improve the performance and generalization of small vision-language models in medical imaging, and how do they affect robustness across different datasets?
What did the authors do?
- Developed ChexReason, a multimodal vision-language model trained on chest X-ray images and reports.
- Used a two-stage training approach: supervised fine-tuning (SFT) with 2,000 samples to generate reasoning traces, followed by reinforcement learning with Group Relative Policy Optimization (GRPO) on 1,000 RL samples.
- Employed a CLIP-based visual encoder and a language model for text generation, with reasoning traces generated by a teacher model (Gemini 2.5) trained on ground-truth labels.
- Fine-tuned the model using Low-Rank Adaptation (LoRA) for parameter efficiency, keeping the visual encoder frozen.
- Designed reward functions to enforce output format and label accuracy, testing variants with different instruction formats.
- Evaluated performance on two datasets: CheXpert and NIH, using macro-F1 and micro-F1 metrics.
- Conducted ablation studies to analyze the impact of instruction formats and training strategies.
What did they find?
- ChexReason improved in-distribution performance on CheXpert by 23% (macro-F1=0.346) but dropped 19% on NIH, indicating a trade-off between optimizing for benchmark datasets and generalization.
- Structured reasoning instructions (Reasoning A) benefited models with general-purpose pretraining like Qwen2.5-VL-3B, while free-form narratives improved domain-specific models like MedGemma-4B.
- R1-style training (fine-tuning followed by RL) tended to overfit to benchmark-specific semantics, reducing transferability to out-of-distribution data.
- The study highlights that aggressive benchmark optimization may harm clinical robustness, which is critical for real-world deployment.
- Limitations include the small training dataset size and the focus on only two datasets, which may not capture the full diversity of clinical data.
Why does this matter?
- Demonstrates that training strategies optimized solely for benchmarks can lead to models that perform well in controlled settings but fail in real-world clinical environments.
- Emphasizes the importance of balancing in-distribution accuracy with cross-dataset robustness, especially in healthcare where patient populations are diverse.
- Suggests that curated supervised fine-tuning may be more effective than aggressive RL-based benchmark optimization for deploying reliable medical AI tools.
- Highlights the need for evaluation methods that better reflect clinical variability to ensure AI models truly benefit patient care.
Key Points
R1-style training improves in-distribution performance but can hurt cross-dataset generalization in medical vision-language models.
Structured reasoning instructions and instruction format significantly impact model transferability.
Overfitting to benchmark semantics reduces robustness, posing challenges for clinical deployment.
Balancing benchmark success with real-world robustness is critical for trustworthy medical AI.
A Medical Multimodal Diagnostic Framework Integrating Vision-Language Models and Logic Tree Reasoning

Image from arXiv paper.
What’s the research question?
How can combining vision-language alignment with structured logic reasoning improve the accuracy and interpretability of multimodal medical diagnosis AI systems?
What did the authors do?
The authors developed a novel diagnostic framework that integrates visual and textual medical data with logical reasoning:
Extended the LLaVA vision-language model by adding explicit logic regularization to enhance reasoning coherence.
Encoded medical images and clinical narratives into a shared representation space, enabling early and direct interaction between visual and textual modalities.
Projected visual tokens into the language model’s hidden space to facilitate joint reasoning over images and text.
Applied a CLIP-style contrastive loss to align visual and textual embeddings, strengthening grounding between modalities.
Generated multiple reasoning chains (rollouts) guided by instruction prompts, capturing diverse diagnostic hypotheses.
Refined these rollouts using a dynamic advantage policy optimizer (DAPO) that balances accuracy, logical consistency, and multimodal grounding.
Parsed each reasoning chain into syllogistic triads to construct verifiable logic trees representing the diagnostic process.
Derived the final diagnosis by aggregating and evaluating these logic trees, providing transparent reasoning paths.
What did they find?
The proposed framework demonstrated significant improvements over baseline models:
Achieved 77.1% accuracy and a ROUGE-L score of 41.6 on the MedXpertQA dataset, outperforming previous methods.
Found that visual input contributed most to diagnostic accuracy, highlighting the importance of image-text interaction.
Showed that explicit logic regularization improved the coherence and verifiability of reasoning chains, making diagnoses more transparent.
Produced stepwise explanations that clearly linked specific image regions to diagnostic conclusions, unlike baseline models that often identified relevant regions without connecting them to the final diagnosis.
Limitations include reliance on the quality of input data and the complexity of parsing reasoning chains into logic trees, which may affect scalability.
Why does this matter?
This work advances multimodal medical AI by combining vision-language alignment with structured, verifiable reasoning, addressing key challenges in accuracy and interpretability:
Enhances trustworthiness of AI diagnoses by providing transparent logic trees that clinicians can verify.
Facilitates integration of diverse medical data types, such as images and clinical notes, into a unified reasoning framework.
Potentially improves clinical decision-making by offering clear, step-by-step diagnostic explanations grounded in multimodal evidence.
Sets a foundation for future AI systems that require both high accuracy and interpretability in complex, real-world medical settings.