- TensorTeach's Newsletter
- Posts
- Learning from Imperfect Humans, Math via Code Generation, Judging with RL, Scaling via Hardware Co-Design, and More
Learning from Imperfect Humans, Math via Code Generation, Judging with RL, Scaling via Hardware Co-Design, and More
TensorTeach AI
May 16, 2025
Reinforced Interactive Continual Learning via Real-time Noisy Human Feedback

Image from arXiv paper — copyright belongs to authors or publishers.
What’s the research question?
How can AI models effectively learn new skills from real-time noisy human feedback while retaining prior knowledge?
What did the authors do?
The authors proposed the RiCL framework, which combines three components to enable continual learning from noisy human feedback:
Temporal Consistency-aware Purifier (TCP): Distinguishes clean from noisy samples by analyzing prediction stability over time using Generalized Cross-Entropy loss and confidence scoring.
Interaction-aware Direct Preference Optimization (IPO): Aligns model behavior with human intent by training on preference datasets constructed from gaps between AI labels and human feedback, using reinforcement learning.
Noise-resistant Contrastive Learning (NCL): Learns robust representations by encouraging similar embeddings for augmented versions of noisy samples.
The training pipeline first applies contrastive learning on noisy data, then preference optimization on purified clean samples.
What did they find?
RiCL achieved strong performance on FewRel and Tacred datasets under realistic noise conditions:
82.70% Average Precision (AP) and 1.69% Average Forgetting (AF) on Tacred.
84.77% AP and 7.90% AF on FewRel.
Outperformed state-of-the-art baselines.
Ablation studies confirmed the importance of each component.
Demonstrated robustness to varying noise levels and task orders, maintaining both accuracy and low forgetting.
Why does this matter?
RiCL advances continual learning by enabling AI systems to learn effectively from noisy, real-time human feedback while retaining prior knowledge. Its novel combination of purification, preference alignment, and contrastive learning addresses key challenges in interactive AI. This paves the way for more adaptive, resilient models in real-world human-in-the-loop applications such as personalized assistants, robotics, and online learning systems.
Key Points
Introduces a framework for continual learning from noisy human feedback.
Combines temporal consistency purification, preference optimization, and contrastive learning.
Achieves state-of-the-art results on noisy relation extraction benchmarks.
Demonstrates robustness to noise and task order variations.
MathCoder-VL: Bridging Vision and Code for Enhanced Multimodal Mathematical Reasoning
What’s the research question?
How can code-based supervision enhance multimodal mathematical reasoning in large vision-language models?
What did the authors do?
The authors developed MathCoder-VL, a multimodal model that aligns mathematical images with executable code to improve reasoning. Their approach involved:
A two-stage training process:
Image-to-code mid-training: Using the ImgCode-8.6M dataset containing 8.6 million pairs of math images and corresponding code (e.g., TikZ, Python) that render these images. This dataset was created via a model-in-the-loop method where an initial image-to-code model generated code verified by execution.
Math instruction fine-tuning: Fine-tuning on the MM-MathInstruct-3M dataset with 3 million multimodal math instruction examples, each including a problem, related image, and step-by-step solution generated by language models.
The model was trained to align visual features with code representations, enhancing understanding of mathematical diagrams and enabling complex problem-solving.
What did they find?
MathCoder-VL achieved state-of-the-art results among open-source models on several benchmarks:
Scored 26.1% on MATH-Vision, 46.5% on MathVerse, and 73.6% on MathVista (GPS).
Outperformed GPT-4o and Claude 3.5 Sonnet specifically on geometry problem-solving tasks.
Ablation studies confirmed that both the image-to-code mid-training and synthetic images contributed significantly to performance improvements.
Demonstrated strong multi-step reasoning and geometric problem-solving capabilities.
Limitations include reliance on synthetic datasets and potential challenges generalizing beyond mathematical domains.
Why does this matter?
By using code as a precise alignment mechanism between images and text, MathCoder-VL introduces a novel paradigm for multimodal mathematical reasoning. This approach advances AI’s ability to interpret and solve complex math problems involving visual and textual information. The large-scale datasets created also provide valuable resources for future research. Applications include AI-assisted STEM education, automated problem-solving tools, and enhanced multimodal AI systems capable of reasoning across modalities.
Key Points
Introduces code-based supervision to align mathematical images with executable code.
Two-stage training on large-scale synthetic datasets enhances multimodal reasoning.
Outperforms leading open-source and proprietary models on geometry and math benchmarks.
Enables multi-step reasoning combining visual and textual modalities.
J1: Incentivizing Thinking in LLM-as-a-Judge via Reinforcement Learning
What’s the research question?
How can reinforcement learning be used to improve the judgment and reasoning capabilities of large language models acting as judges?
What did the authors do?
The authors proposed J1, a framework that trains LLMs to act as judges by evaluating paired responses through structured reasoning and reinforcement learning:
LLMs generate chain-of-thought (CoT) reasoning before making judgments, outlining evaluation criteria and comparing responses.
Training uses synthetic preference pairs for verifiable and non-verifiable tasks, avoiding reliance on human-labeled data.
Employs Group Relative Policy Optimization (GRPO), a PPO variant that estimates baselines from group-level returns for efficient online RL without a separate critic.
Mitigates position bias by training on both response orders and introducing a verdict consistency reward to encourage stable judgments.
Two variants were trained: Pairwise-J1 (direct comparison) and Pointwise-J1 (individual scoring).
Evaluated on benchmarks including PPE, JudgeBench, RM-Bench, FollowBenchEval, and RewardBench.
What did they find?
J1-Llama-70B achieved strong results:
69.6% accuracy on PPE, outperforming EvalPlanner and DeepSeek-GRM-27B.
60.0% on JudgeBench, a 14% improvement over a distilled baseline.
82.7% on RM-Bench and 93.3% on RewardBench.
Both variants improved position-consistent accuracy with more sampling.
Ablations showed the importance of consistency rewards and high-quality prompts.
Limitations include dependence on synthetic data quality and potential challenges scaling to more complex judgment tasks.
Why does this matter?
J1 provides a scalable method to train LLMs as reliable and interpretable judges without human-labeled data, addressing key challenges like position bias. This advances AI alignment and evaluation by enabling models to reason through judgments with verifiable rewards. The framework has broad implications for improving AI evaluation, fairness, and downstream applications requiring robust decision-making.
Key Points
Trains LLMs to judge responses using chain-of-thought reasoning and reinforcement learning.
Eliminates need for human-labeled data via synthetic preference pairs.
Introduces methods to reduce position bias and improve verdict consistency.
Demonstrates strong performance across multiple judgment benchmarks.
Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures
What’s the research question?
How can hardware-aware model co-design address the scaling challenges in training and inference of large language models?
What did the authors do?
The authors present an enhanced DeepSeek-V3 trained with a hardware-aware co-design approach to optimize scalability and efficiency. Trained on 2,048 NVIDIA H800 GPUs with a focus on integrating model architecture and hardware design.
Key architectural innovations of DeepSeek-V3:
Multi-head Latent Attention (MLA): Compresses Key-Value caches by projecting them to a lower-dimensional latent space, reducing memory usage during inference.
DeepSeekMoE: A Mixture-of-Experts model activating only a subset of experts per token to reduce computation.
FP8 Mixed-Precision Training: Uses 8-bit floating-point precision to lower memory and compute requirements.
Multi-Plane Fat-Tree Network: A two-layer network topology assigning each GPU-NIC pair to distinct planes, improving scalability and reducing network overhead.
Training pipeline includes forward/backward passes with FP8, expert routing via all-to-all communication, and memory optimizations.
Inference optimizations include speculative decoding and overlapping computation with communication.
Performance evaluated via perplexity, throughput, latency, and ablation studies on each component.
What did they find?
DeepSeek-V3 with hardware optimization demonstrated:
KV cache size reduced to 70 KB per token, significantly smaller than Qwen-2.5 (327 KB) and LLaMA-3.1 (516 KB).
Training cost of 250 GFLOPS per token, much lower than dense models.
Inference throughput of 67 tokens/second with a theoretical upper bound of 1,200 tokens/second.
Network topology enabled scaling to 16,384 GPUs with low latency and high bandwidth.
Ablations showed minimal accuracy loss from FP8 quantization and confirmed the importance of each architectural innovation.
Limitations include the complexity of hardware-software co-design and potential challenges generalizing to other hardware platforms.
Why does this matter?
This work provides a practical blueprint for scalable, cost-efficient training and inference of large language models by tightly integrating model architecture with hardware design. The innovations in attention compression, expert routing, low-precision training, and network topology address critical bottlenecks in AI system scaling. This advances the state of the art in efficient AI architectures, enabling broader deployment and experimentation with large models.
Key Points
Hardware-aware co-design enables efficient scaling of large language models.
Introduces Multi-head Latent Attention to compress KV caches.
Uses Mixture-of-Experts and FP8 precision for reduced computation and memory.
Novel network topology supports scaling to thousands of GPUs with low latency.
Towards a Deeper Understanding of Reasoning Capabilities in Large Language Models
What’s the research question?
To what extent can LLM agents autonomously learn and adapt to novel tasks in dynamic environments?
What did the authors do?
The study evaluated open-source LLMs on dynamic decision-making tasks using advanced prompting strategies:
Tested models: Llama3-8B, Mistral-Nemo-12b, DeepSeek-R1-14b, and Llama3.3-70B.
Benchmark: SmartPlay, with tasks including TwoArmedBandit, Rock Paper Scissors, Tower of Hanoi, and Messenger.
Prompting strategies:
Reflection: Retrospective analysis of past actions.
Oracle: Heuristic mutation via evolutionary strategies.
Planner: Forward-looking action planning simulating future steps.
Evaluation metrics: Task-specific measures such as cumulative rewards and success rates.
Ablation studies: Investigated the impact of prompt length and model size on performance.
What did they find?
Key findings include:
Llama3.3-70B consistently outperformed smaller models across all tasks.
In TwoArmedBandit, it scored 48.00 with Reflection + Planner, while smaller models struggled with complex prompts.
Rock Paper Scissors adaptation improved from 22.20 to 30.00.
Achieved a perfect score of 2.00 in Tower of Hanoi using Reflection + Oracle.
Smaller models benefited from advanced prompting but exhibited instability and variable performance.
Excessive reasoning degraded performance in smaller models, emphasizing the importance of prompt design.
Why does this matter?
This research clarifies how advanced prompting strategies affect LLM reasoning and adaptation in dynamic environments. It underscores the critical role of model size and prompt engineering in achieving robust autonomous behavior. The insights guide the development of more effective LLM agents capable of multi-step reasoning and planning, with applications in interactive AI, robotics, and decision support systems.
Key Points
Evaluates LLM agents on dynamic tasks using advanced prompting techniques.
Larger models show more robust reasoning and planning capabilities.
Smaller models can improve with careful prompt design but face instability.
Highlights trade-offs between reasoning depth and model size.
Improving the Reliability of LLMs: Combining Chain-of-Thought Reasoning and Retrieval-Augmented Generation

Image from arXiv paper — copyright belongs to authors or publishers.
What’s the research question?
How can the combination of Chain-of-Thought reasoning and Retrieval-Augmented Generation improve the reliability and reduce hallucinations in large language models?
What did the authors do?
The authors investigated the integration of Chain-of-Thought (CoT) reasoning with Retrieval-Augmented Generation (RAG) to enhance LLM reliability:
Chain-of-Thought reasoning: Encourages models to generate intermediate reasoning steps for complex problem-solving.
Retrieval-Augmented Generation: Supplements model knowledge by retrieving relevant external documents from a vector database (Pinecone) using semantic search.
Documents are chunked, embedded, and indexed for efficient retrieval, then integrated into the model input to ground responses in factual information.
Additional strategies included:
Self-consistency: Generating multiple outputs and selecting the most consistent answer.
Self-verification: Prompting the model to critique and validate its own responses against retrieved evidence.
The framework was evaluated on HaluEval, FEVER, and TruthfulQA benchmarks using GPT-3.5-Turbo, LLaMA-2-7B, and DeepSeek-R1 models.
What did they find?
Results showed significant improvements:
RAG+CoT with GPT-3.5-Turbo reduced hallucination rate to 11% on HaluEval.
Self-verification achieved 90% accuracy on FEVER and 80% MC2 score on TruthfulQA.
All methods outperformed baseline models, with RAG+CoT and self-verification being the most effective.
LLaMA-2 slightly outperformed GPT-3.5-Turbo in self-verification, possibly due to architectural advantages.
Why does this matter?
This work demonstrates that combining structured reasoning with retrieval-based grounding substantially enhances the factual accuracy and trustworthiness of LLM outputs. The scalable framework reduces hallucinations and enables models to internally assess and improve their answers, advancing the reliability of AI-generated content in real-world applications such as question answering, fact-checking, and knowledge-intensive tasks.
Key Points
Combines Chain-of-Thought reasoning with Retrieval-Augmented Generation to improve LLM reliability.
Introduces self-consistency and self-verification strategies to reduce hallucinations.
Achieves state-of-the-art accuracy and low hallucination rates on multiple benchmarks.
Provides a scalable framework for grounding LLM outputs in factual evidence.
WorldView-Bench: A Benchmark for Evaluating Global Cultural Perspectives in Large Language Models

Image from arXiv paper — copyright belongs to authors or publishers.
What’s the research question?
How can the cultural inclusivity of large language models (LLMs) be effectively evaluated and enhanced?
What did the authors do?
The authors developed WorldView-Bench, a benchmark and evaluation framework to assess and improve cultural inclusivity in LLMs:
Constructed 175 open-ended questions across seven categories: Ethical/Moral, Religious, Lifestyle, Cultural Norms, Traditions, History, and Technology.
Evaluation pipeline included three components:
Cultural References Extraction: Uses GPT-4o to identify and classify cultural perspectives in model responses.
Perspectives Distribution Score (PDS) and Entropy: Quantifies representation and diversity of cultural viewpoints.
Cultural Sentiment Analysis: Assesses sentiment toward each culture to detect bias or appreciation.
Two intervention strategies were tested:
Contextually-Implemented Multiplex LLMs: Embeds multiplexity principles via system prompts encouraging multiple cultural viewpoints.
MAS-Implemented Multiplex LLMs: Uses a Multi-Agent System where agents represent distinct cultural perspectives, and a coordinator synthesizes a unified, inclusive response.
The MAS system was implemented using the Camel AI framework with GPT-4o agents.
What did they find?
Baseline LLMs showed low cultural inclusivity with PDS entropy of 0.13.
Contextual multiplexity raised entropy to 0.26, reflecting improved diversity of perspectives.
The MAS approach achieved near-equal representation across cultures with entropy of 0.94.
Sentiment analysis revealed a shift from neutral/negative to more positive sentiment, particularly with MAS.
Limitations include reliance on GPT-4o for evaluation and challenges in capturing more nuanced cultural contexts.
Why does this matter?
WorldView-Bench provides a novel, generative framework for measuring and improving cultural fairness in LLMs. By leveraging multiplexity and multi-agent collaboration, it offers practical methods to mitigate cultural bias and foster inclusivity. This supports the development of globally aware AI systems that respect and reflect diverse cultural perspectives—crucial for ethical and responsible AI deployment worldwide.
Key Points
Introduces a benchmark to evaluate cultural inclusivity in LLMs across multiple domains.
Uses GPT-4o for extracting cultural references, diversity scoring, and sentiment analysis.
Demonstrates that multiplexity principles and multi-agent systems improve inclusivity.
Provides tools for mitigating cultural bias and promoting fairness in AI.
Achieving Scalable Robot Autonomy via Neurosymbolic Planning Using Lightweight Local LLM
What’s the research question?
How can lightweight local large language models (LLMs) be effectively utilized for scalable neurosymbolic planning in robot autonomy?
What did the authors do?
The authors introduced the Gideon framework to enable neurosymbolic planning for robot autonomy using lightweight local LLMs:
General Problem Generator: Creates domain-problem instances in PDDL 2.1 format based on user-defined rules.
Plan Generator: Uses the Probe satisficing planner with depth-first search to generate and validate plans.
Dataset Generator: Structures instruction–input–output tuples into Alpaca JSON format for fine-tuning.
Fine-tuned the Qwen-2.5 1.5B model on these datasets in both single-domain and multi-domain settings.
Evaluated planning validity using the VAL tool to check adherence to domain constraints and successful goal completion.
What did they find?
The single-domain model achieved 66.1% valid plans.
The multi-domain model reached 70.6% validity overall, including:
83.0% in NO-MACRO domains
58.2% in MACRO domains
Multi-domain training served as regularization, improving generalization across tasks.
The Qwen-2.5 model, at only 1.5B parameters and 120× smaller than GPT-3, showed competitive neurosymbolic planning capabilities.
Why does this matter?
Gideon demonstrates that high-quality neurosymbolic planning can be achieved using lightweight, locally deployable LLMs. This reduces dependence on large, cloud-based models and enables scalable, efficient, and low-latency robot autonomy. It has important implications for robotics applications in resource-constrained environments and for multi-domain autonomy across diverse tasks.
Key Points
Introduces a neurosymbolic planning framework using lightweight local LLMs.
Combines problem generation, plan synthesis, and dataset creation for training.
Demonstrates strong planning validity in single- and multi-domain settings.
Enables scalable robot autonomy with reduced reliance on large cloud models.
How Hungry is AI? Benchmarking Energy, Water, and Carbon Footprint of LLM Inference

Image from arXiv paper — copyright belongs to authors or publishers.
What’s the research question?
How can the environmental footprint of large language model (LLM) inference be accurately benchmarked across different models and deployment infrastructures?
What did the authors do?
The authors developed a comprehensive benchmarking framework that integrates model performance with infrastructure-specific environmental multipliers to estimate the energy, water, and carbon footprints of LLM inference:
Analyzed 30 LLMs with associated deployment contexts, hardware types, and environmental multipliers:
PUE (Power Usage Effectiveness)
WUE (Water Usage Effectiveness)
CIF (Carbon Intensity Factor)
Measured per-query energy consumption using:
Latency
Tokens-per-second
GPU/non-GPU power draw
Utilization rates
Attributed models to hardware classes and estimated usage through statistical inference and public benchmarks.
Calculated water consumption and carbon emissions, focusing on operational (Scope 2) impacts.
Applied Data Envelopment Analysis (DEA) to assess eco-efficiency—measuring environmental inputs relative to model performance using the AI Index.
What did they find?
GPT-4.1 nano was the most energy-efficient, consuming only 0.454 Wh per long prompt.
o3 and DeepSeek-R1 were among the most energy-intensive, exceeding 33 Wh per long prompt.
Claude-3.7 Sonnet ranked highest in overall eco-efficiency.
A case study on GPT-4o revealed that 700 million daily queries could:
Consume electricity equivalent to 35,000 U.S. homes
Evaporate enough freshwater for 1.2 million people
Emit carbon requiring a Chicago-sized forest to offset
Highlighted a scaling paradox: even efficient models can have massive environmental impacts due to high usage volume.
Why does this matter?
This study introduces the first standardized, infrastructure-aware framework for assessing the environmental footprint of LLM inference. By linking fine-grained performance metrics with environmental data and eco-efficiency analysis, it provides transparent, actionable insights into the sustainability of AI systems. This enables more responsible AI deployment, supports regulatory policy development, and encourages innovation in greener AI technologies.
Key Points
Introduces an infrastructure-aware benchmarking framework for LLM environmental impact.
Analyzes energy, water, and carbon footprints across 30 models and deployment settings.
Applies Data Envelopment Analysis for eco-efficiency evaluation.
Highlights large-scale environmental implications of widespread LLM usage.
Pre-Act: Multi-Step Planning and Reasoning Improves Acting in LLM Agents
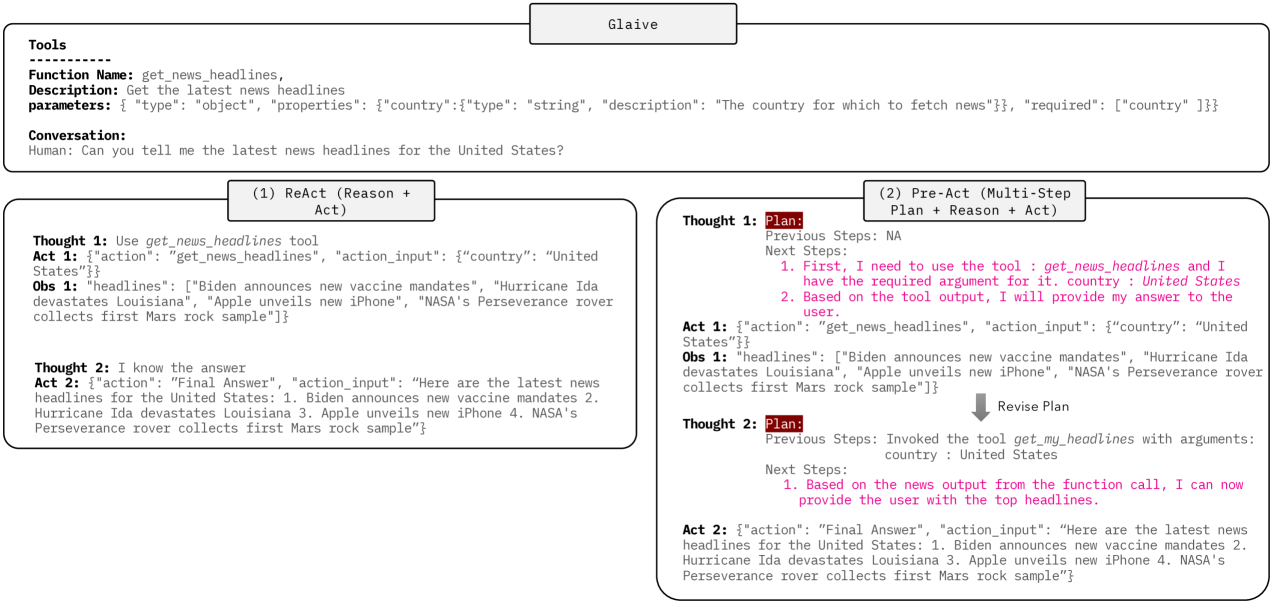
Image from arXiv paper — copyright belongs to authors or publishers.
What’s the research question?
How does multi-step planning and reasoning affect the performance of LLM agents in task-oriented scenarios?
What did the authors do?
The authors proposed Pre-Act, a structured multi-step planning framework that enhances LLM agents’ reasoning and acting capabilities:
Extends the ReAct paradigm by generating a sequential plan with detailed reasoning for each step, including actions and tool calls with rationales.
Integrates tool outputs into context to allow for dynamic plan refinement.
Training strategy:
Initial Fine-Tuning: Trained models on the Glaive dataset using ReAct to learn basic tool usage.
Progressive Refinement: Further fine-tuned on a proprietary dataset with explicit reasoning annotations in the Pre-Act format.
Evaluation: Performance measured at the turn level (action recall, tool call accuracy) and end-to-end (task completion), with GPT-4 as the judge.
What did they find?
The fine-tuned Llama 3.1 70B model achieved:
0.9929 action recall
0.9848 tool call F1 score
0.9586 answer similarity
→ All surpassing GPT-4.
On the Almita dataset, Pre-Act achieved:
0.82 goal completion
0.89 progress rate
→ Outperformed both GPT-4 with ReAct and GPT-4 with Pre-Act.
Structured multi-step planning enabled smaller models to match or exceed performance of larger proprietary LLMs.
Why does this matter?
Pre-Act advances agentic AI by showing that explicit multi-step planning and reasoning significantly improve task-oriented performance. The scalable training method reduces dependency on massive proprietary models, democratizing access to advanced agent capabilities. Its dual-level evaluation and use of GPT-4 as an assessment tool offer a strong foundation for future research on interactive and tool-using AI agents.
Key Points
Introduces multi-step planning with detailed reasoning for LLM agents.
Uses curriculum learning to fine-tune models progressively.
Achieves superior performance to GPT-4 on action and task completion metrics.
Provides a comprehensive evaluation framework using GPT-4 as judge.