- TensorTeach's Newsletter
- Posts
- Input-Time Scaling Breakthroughs, LoRA Distillation for Math Skills, Datarus-R1 Data Agent, Traffic Video AI Improves Safety
Input-Time Scaling Breakthroughs, LoRA Distillation for Math Skills, Datarus-R1 Data Agent, Traffic Video AI Improves Safety
TensorTeach AI
August 22, 2025
Input-Time Scaling: A Paradigm for Improving Reasoning in Large Language Models
What’s the research question?
Can input-time scaling improve reasoning abilities in large language models without relying on extensive data and complex training pipelines?
What did the authors do?
The authors introduced a new approach called Input-Time Scaling, which focuses on refining input queries during both training and testing to boost reasoning performance in large language models (LLMs). Their methodology involved:
Curating datasets from OpenThoughts and LIMO, applying four input modification strategies: No-Persona, Persona-Similar, Persona-Unsimilar, and Persona-Random.
Generating personas automatically using meta-cognition techniques to create diverse and challenging input queries.
Fine-tuning LLMs on these persona-enhanced datasets during training.
Applying the same persona strategies during inference to test queries.
Evaluating the models on math reasoning benchmarks AIME24 and AIME25, measuring pass@1 accuracy.
Comparing their approach to state-of-the-art models like DeepSeek-R1-Distill-Qwen-32B and LIMO.
What did they find?
The Input-Time Scaling approach yielded impressive results:
Achieved 76.7% pass@1 accuracy on AIME24 and AIME25 with only 1,000 training examples.
Using a majority vote of three models boosted performance to 80% on AIME25.
Starting from a strong baseline (DeepSeek-R1-Distill-Qwen-32B), the best combined result was 86.6% on AIME24 and 76.7% on AIME25.
Outperformed previous models like S1-32B (56.7%) and LIMO-32B (49.3%) by a large margin.
Found that training with Persona-Similar and Persona-Unsimilar strategies, which emphasize diversity, led to the highest performance.
Why does this matter?
This work introduces a novel paradigm for enhancing reasoning in large language models by shifting focus from just data quantity and quality to input refinement at inference time. The key insights include:
Highlighting the importance of diversity in input queries to challenge models and improve reasoning.
Demonstrating that simple, transparent input modifications can lead to significant performance gains without massive data or complex retraining.
Providing a practical and scalable approach that can be easily integrated into existing LLM workflows.
Opening new avenues for research into input-centric methods to boost reasoning and problem-solving capabilities in AI models.
Key Points
Input-Time Scaling refines input queries during training and inference to improve reasoning.
Using diverse personas in inputs enhances model performance on math reasoning benchmarks.
Achieves state-of-the-art results with minimal training data (1k examples).
Challenging traditional focus on data quantity by emphasizing input diversity and refinement.
Can Large Models Teach Student Models to Solve Mathematical Problems Like Human Beings? A Reasoning Distillation Method via Multi-LoRA Interaction
What’s the research question?
Can a novel multi-LoRA interaction method improve the mathematical reasoning abilities of small language models (SLMs) by mimicking human teaching and learning patterns?
What did the authors do?
The authors introduced a new framework called LoRID that enhances small language models’ (SLMs) ability to solve math problems by emulating how humans teach and learn. Their approach involves several key components:
Teacher Model Generation: A large, powerful teacher model generates high-quality, knowledge-rich datasets for training.
System 1 (Intuitive Reasoning) – Intuitive Reasoner (IR): Produces Chain-of-Thoughts (CoT) to break down problems into step-by-step reasoning.
System 2 (Deep Reasoning) – Knowledge Generator (KG) and Deep Reasoner (DR): KG extracts relevant knowledge from the question, while DR applies this knowledge to generate solutions.
Interaction During Inference: IR and DR modules generate answers independently but compare their outputs for consistency. If inconsistent, they iteratively refine their answers until they agree or reach a maximum number of attempts.
What did they find?
The LoRID framework achieved impressive results:
State-of-the-art performance on the GSM8K math reasoning dataset, outperforming previous methods by 2.3% to 16.1% across five different base models.
Consistent and significant improvements when integrated with four strong baseline systems.
Ablation studies confirmed that both the intuitive (System 1) and deep reasoning (System 2) components are crucial for success.
Robustness across different model sizes and training data volumes, demonstrating broad applicability.
Limitations include reliance on high-quality knowledge from teacher models, additional computational overhead due to iterative inference, and testing primarily on math reasoning tasks, leaving generalization to other domains open for future work.
Why does this matter?
This work introduces a novel way to empower smaller language models to perform complex mathematical reasoning by mimicking human teaching and learning patterns. The multi-LoRA interaction framework enables models to combine quick, intuitive reasoning with deep, knowledge-based problem solving, leading to better accuracy and robustness. This approach has several important implications:
AI Education: Smaller models can become more effective tutors and problem solvers, making advanced AI-powered educational tools more accessible and affordable.
Knowledge Transfer: The modular interaction between reasoning modules offers a new paradigm for training AI systems, especially in resource-constrained settings where large models are impractical.
Broader AI Capabilities: While demonstrated on math problems, the framework’s principles could extend to other reasoning domains, such as science, language understanding, or decision-making.
Industry Impact: The approach’s modularity and efficiency make it attractive for deployment in sectors like healthcare, finance, and education, where nuanced reasoning is critical.
Key Points
LoRID combines intuitive and deep reasoning modules via multi-LoRA interaction to improve small language models’ math problem-solving.
State-of-the-art results on GSM8K, outperforming existing methods significantly.
Modules interact iteratively during inference to reinforce correct reasoning and correct errors.
Framework is robust across different model sizes and training data volumes, with potential for broader reasoning applications.
Datarus-R1: An Adaptive Multi-Step Reasoning LLM for Automated Data Analysis
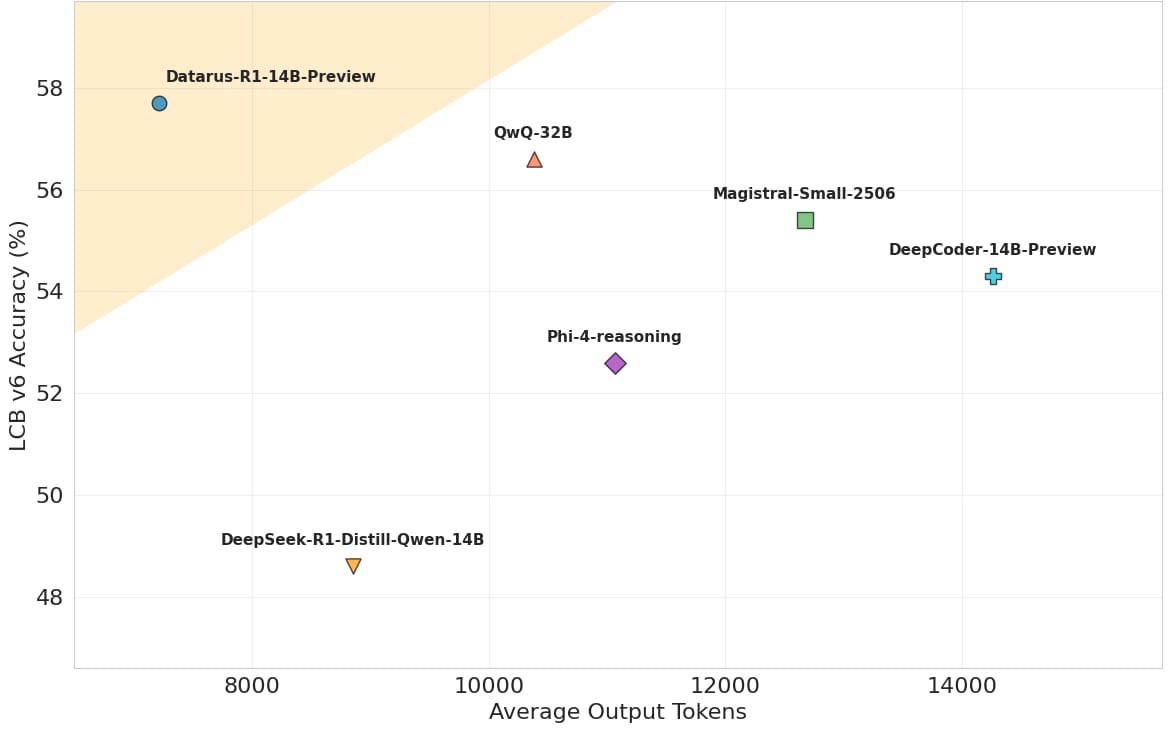
Image from arXiv paper.
What’s the research question?
How can a large language model be trained to perform effective multi-step reasoning in data analysis tasks?
What did the authors do?
The authors developed Datarus-R1-14B, a 14-billion-parameter language model fine-tuned specifically for complex data analysis through multi-step reasoning:
Trained on 144,000 synthetic problem-solving trajectories generated from 20,000 datasets spanning finance, medicine, and numerical analysis.
Each trajectory includes detailed reasoning steps, code execution, error traces, and reflections, formatted in a structured notebook style.
Utilized a ReAct-style approach with explicit tags (, , , ) to clearly delineate reasoning and tool use.
Implemented a dual reward system combining a structural reward (favoring correct reasoning step placement) with a Hierarchical Reward Model (HRM) that scores both individual steps and entire trajectories based on semantic correctness and coherence.
Adopted an adaptive curriculum that gradually shifts emphasis from structural to semantic rewards during training.
Operated in two modes: agentic mode generating reasoning steps with embedded tool calls for live code execution, and reflection mode producing concise / pairs.
Optimized training efficiency using a Group Relative Policy Optimization (GRPO) algorithm with distributed generation, KV-cache reuse, and model sharding.
What did they find?
Datarus-R1-14B demonstrated significant improvements over comparable models:
Outperformed similar-sized models on benchmarks like LiveCodeBench, AIME 2024/2025, and GPQA Diamond.
Achieved up to 30% higher accuracy on AIME and reduced token usage by 18-49% per solution, showcasing improved efficiency.
Excelled at difficult tasks where other models' verbosity increased dramatically (e.g., Phi-4-reasoning tokens grew from 2,159 to 20,399).
Displayed effective hypothesis refinement by revising initial solutions after errors and converging on correct answers within 1-2 iterations.
Exhibited emergent behaviors such as tag co-occurrence and error signature recognition, indicating robust internalization of reasoning patterns.
Limitations include reliance on synthetic data trajectories, which may differ from real-world data complexity, and the need for further testing on diverse, real-world datasets.
Why does this matter?
This work advances the field of AI reasoning and data analysis by:
Introducing a process-centric training approach that emphasizes reasoning steps and tool use, leading to more interpretable and reliable AI systems.
Combining structured reasoning trajectories with hierarchical rewards to better capture the quality of complex problem-solving.
Enhancing token efficiency and accuracy, making large language models more practical for real-world data analysis and automated reporting tasks.
Contributing innovations in structured training, adaptive curriculum, and distributed generation that can inform future development of scalable, robust reasoning agents.
Potential applications include automated data analysis, financial modeling, medical diagnostics, and scientific research where multi-step reasoning is critical.
Key Points
Developed Datarus-R1-14B, a large language model trained on structured, multi-step data analysis trajectories.
Used a dual reward system combining structural and semantic evaluation to improve reasoning quality.
Achieved up to 30% higher accuracy and 49% token reduction on complex benchmarks.
Demonstrated effective hypothesis refinement and emergent reasoning behaviors.
Structured Prompting and Multi-Agent Knowledge Distillation for Traffic Video Interpretation and Risk Inference
What’s the research question?
Can combining structured prompting with multi-agent knowledge distillation improve the performance of lightweight vision-language models in understanding traffic scenes and assessing risks?
What did the authors do?
The authors developed a novel framework that leverages two large vision-language models (VLMs) acting as agents to enhance traffic video analysis:
Agent 1: Performs structured scene interpretation across six semantic dimensions—time of day, weather, pavement wetness, vehicle behavior, traffic flow and speed, and congestion—using tailored Chain-of-Thought prompts to generate rich, semantically annotated descriptions.
Agent 2: Conducts risk interpretation based on Agent 1’s outputs, evaluating environmental risks, vehicle behavior risks, traffic flow risks, and overall safety, providing actionable insights like alerts and safe speed recommendations.
The outputs from both agents are combined into high-quality, knowledge-enriched pseudo-annotations.
These pseudo-annotations are used to fine-tune a smaller, efficient vision-language model (Qwen2.5-VL-3B), called VISTA, via supervised fine-tuning so it can generate structured scene and risk reports directly from input frames.
The framework was evaluated on 200 traffic video clips, comparing VISTA’s generated reports to GPT-4o references using BLEU-4, METEOR, ROUGE-L, and CIDEr metrics.
What did they find?
VISTA significantly outperformed baseline models:
Achieved BLEU-4=0.3289, METEOR=0.5634, ROUGE-L=0.4895, CIDEr=0.7014, and a composite score of 36.30.
Outperformed the original 3B pretrained vision-language model and variants fine-tuned on individual components, demonstrating the benefit of joint optimization.
Showed strong semantic grounding, fluency, and alignment with human-like multi-step descriptions.
Limitations include evaluation on a relatively small test set and reliance on large base models as teachers, which may impact scalability.
Why does this matter?
This work advances the development of lightweight, interpretable vision-language models capable of real-time traffic scene understanding and risk inference. By effectively transferring knowledge from large, complex models to smaller, efficient ones, the framework addresses a key challenge in deploying AI for edge devices and intelligent transportation systems. The combination of structured prompting and multi-agent knowledge distillation enables scalable, high-performance models that can provide detailed, actionable insights in dynamic traffic environments, potentially improving safety and traffic management in the real world.
Key Points
Combines structured scene interpretation with risk assessment using two large vision-language agents.
Uses knowledge distillation to train a compact, efficient model for traffic video analysis.
Achieves state-of-the-art performance on traffic scene understanding metrics.
Facilitates deployment of interpretable AI models in real-time transportation applications.
Standardization of Neuromuscular Reflex Analysis — Role of Fine-Tuned Vision-Language Model Consortium and OpenAI gpt-oss Reasoning LLM Enabled Decision Support System

Image from arXiv paper.
What’s the research question?
Can a hybrid AI system combining fine-tuned vision-language models and reasoning large language models improve the analysis and diagnosis of neuromuscular reflexes, such as the H-reflex?
What did the authors do?
The authors developed an innovative AI platform to enhance neuromuscular reflex analysis, featuring four key components:
Data Lake: Stored multimodal data including EMG waveform images, athlete metadata, and clinical observations.
Fine-Tuned Vision-Language Models (VLMs): Used Llama-Vision, Pixtral-Vision, and Qwen2-VL, fine-tuned with the Unsloth library employing QLoRA and 4-bit quantization for efficiency.
LLM Agent: Orchestrated communication and prompt engineering among models.
Reasoning Layer: The OpenAI-gpt-oss large language model integrated VLM outputs to generate a coherent, explainable neuromuscular assessment.
By combining detailed image and metadata analysis with advanced reasoning, the system aimed to produce accurate and interpretable diagnoses.
What did they find?
The hybrid system demonstrated several notable strengths:
Improved Prediction Accuracy: Fine-tuned VLMs showed significant enhancements in predicting neuromuscular states, with higher precision and consistency compared to baseline models.
Effective Integration and Reasoning: The OpenAI-gpt-oss LLM successfully synthesized diverse VLM outputs into unified, coherent assessments, showcasing robust reasoning capabilities.
High Interpretability: The system provided transparent explanations of its diagnoses, aiding clinical understanding and trust.
Limitations: The study focused on neuromuscular reflexes like the H-reflex; further validation on broader reflex types and larger datasets is needed to confirm generalizability.
Why does this matter?
This work represents a significant advance in neuromuscular diagnostics by integrating multimodal data analysis with powerful reasoning AI. The platform offers a scalable and automated solution that can improve diagnostic accuracy, consistency, and interpretability in both clinical and sports medicine settings. By enabling more reliable assessments and supporting personalized interventions, it has the potential to enhance patient outcomes, facilitate real-time monitoring, and accelerate research into neuromuscular health.
Key Points
Combines fine-tuned vision-language models with a reasoning large language model for neuromuscular reflex analysis.
Uses a four-layer architecture: Data Lake, VLMs, LLM Agent, and Reasoning Layer.
Achieves high accuracy and interpretability in diagnosing neuromuscular states like the H-reflex.
Advances scalable, automated neuromuscular diagnostics with potential clinical and sports applications.