- TensorTeach's Newsletter
- Posts
- Google UCP, Anthropic Agents, DeepMind Robotics, OpenAI Device
Google UCP, Anthropic Agents, DeepMind Robotics, OpenAI Device
The week’s biggest AI moves across commerce, work automation, humanoid robots, and AI-native hardware.
TensorTeach AI
January 23, 2026
My apologies for the delayed newsletter! I was traveling this past week and wasn’t able to get to it. Next week we’ll return to the normal schedule: Tuesday @ 5pm EST.
This Week In AI
Over the past week, major AI progress centered on agents, commerce standards, robotics, regulation, and AI infrastructure. Google announced the Universal Commerce Protocol (UCP), an open standard aimed at enabling AI agents to complete shopping and checkout across retailers. In parallel, Mastercard pushed forward on standards for AI-driven payments, seeking secure, auditable “agent checkout” workflows that can operate at scale.
On the product side, Anthropic advanced desktop agent capabilities with its Cowork research preview and the launch of Anthropic Labs, signaling faster experimentation with tools that can perform real tasks across user files and workflows.
In robotics, Boston Dynamics partnered with Google DeepMind to bring Gemini Robotics models into the Atlas humanoid platform—another strong sign that foundation models are moving into embodied, physical systems.
Regulation also accelerated: South Korea enacted a comprehensive national AI framework (AI Basic Act) emphasizing transparency and labeling of AI-generated content.
Finally, AI infrastructure constraints stayed visible: Intel highlighted difficulty meeting surging AI data-center demand, while reporting suggested OpenAI (with Jony Ive) is targeting an AI-focused device in the second half of 2026—pointing to the next wave of AI-native hardware.
This Week In AI Research
Improving Training Efficiency and Reducing Maintenance Costs via Language Specific Model Merging
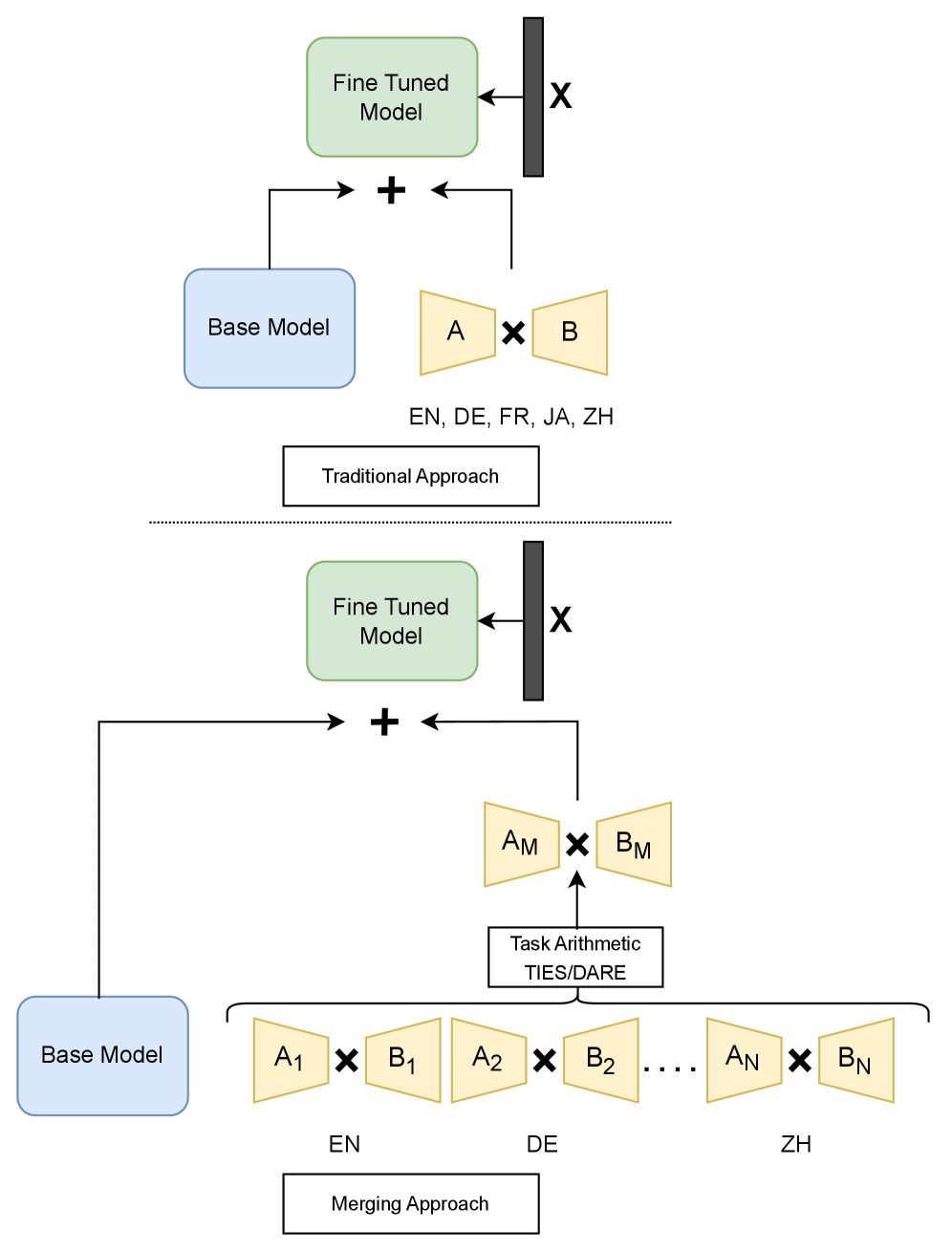
Image from arXiv paper.
What’s the research question?
Can language-specific model merging improve training efficiency and reduce maintenance costs in multilingual large language models?
What did the authors do?
- Compared traditional combined dataset fine-tuning with a novel language-specific model merging approach.
- Used the Llama-3.1-8b-Instruct model fine-tuned on three tasks: Text Summarization, Commonsense Reasoning, and Sentiment Analysis.
- Included five languages: English, German, French, Japanese, and Chinese.
- Applied three merging techniques: TIES (top-k weights selection), DARE (dropout and rescaling), and KnOTS (singular value decomposition).
- Tuned hyperparameters such as weight vectors and weight density (percentage of weights retained).
- Evaluated performance using ROUGE scores (summarization), accuracy (reasoning), and F1 scores (sentiment analysis).
- Measured efficiency by training time and costs during initial setup and updates.
What did they find?
- Merged models achieved comparable performance to traditional combined models across all tasks, with some languages showing improvements.
- In Text Summarization, BertScore improved by 0.1–0.6%.
- In Commonsense Reasoning, merged models outperformed baselines by 0.4–2.2%.
- In Sentiment Analysis, the combined model performed best overall, but some merged models outperformed individual language models.
- Merging reduced initial training time by 35% and update costs by over 70%.
- Limitations include slightly lower performance in some cases and the need for hyperparameter tuning for each merging technique.
Why does this matter?
- Demonstrates that language-specific model merging can maintain high performance while significantly reducing training and maintenance costs.
- Offers a scalable and cost-effective solution for deploying multilingual large language models in industry.
- Enables more efficient updates and expansion to additional languages without retraining entire models from scratch.
Key Points
Language-specific model merging achieves performance parity with traditional combined models across multiple tasks and languages.
Reduces initial training time by 35% and update costs by over 70%, lowering operational expenses.
Uses innovative merging techniques (TIES, DARE, KnOTS) to effectively combine language-specific models.
Supports scalable deployment of multilingual LLMs with less computational and financial overhead.
VideoThinker: Building Agentic VideoLLMs with LLM-Guided Tool Reasoning

Image from arXiv paper.
What’s the research question?
How can agentic tools and synthetic data improve long-form video understanding in Video Large Language Models (VideoLLMs)?
What did the authors do?
The authors introduced VideoThinker, a novel approach to enhance VideoLLMs' ability to understand long videos by integrating agentic tools and synthetic training data:
Agentic tools: Two key tools were developed:
Temporal Retrieval: Finds relevant video segments using semantic similarity between clips and subtitles.
Temporal Zoom: Enables detailed examination of specific intervals through Frame Zoom and Subtitle Zoom.
Synthetic tool-interaction trajectories: The model generates multi-step sequences of tool use in caption space, simulating how an agent would interact with video content.
Grounding back to video: These caption-based sequences are converted into actual video frames, creating a large-scale interleaved dataset of video and tool reasoning.
Fine-tuning VideoLLMs: The model is trained on this synthetic dataset to actively retrieve and perceive key frames during reasoning, improving its understanding of long videos.
Confidence-gated tool controller: An adaptive mechanism triggers multi-round tool reasoning only when the model's confidence drops below a threshold, balancing efficiency and accuracy.
What did they find?
VideoThinker achieved strong performance across multiple benchmarks:
54.8% accuracy on MLVU
48.9% on LVBench
53.7% on VideoMME
59.7% on LongVideoBench
Compared to open-source models, VideoThinker outperformed them and was competitive with closed-source systems and LLM-based agents. Ablation studies showed:
Increasing the number of sampled frames improved accuracy.
Adaptive confidence thresholds optimized the trade-off between speed and performance.
Limitations include reliance on synthetic data generation and the need for further testing on diverse long-video datasets.
Why does this matter?
This work demonstrates that synthetic, tool-augmented training data can significantly boost the ability of VideoLLMs to understand complex, long-form videos. The adaptive reasoning approach allows models to efficiently focus on relevant content while maintaining high accuracy. These advances are crucial for applications like video summarization, content retrieval, and autonomous agents that need to interpret extended video streams in real-world scenarios, paving the way for more intelligent and responsive video understanding systems.
Knowledge Graphs are Implicit Reward Models: Path-Derived Signals Enable Compositional Reasoning

Image from arXiv paper.
What’s the research question?
Can knowledge graphs be leveraged as implicit reward signals to enhance the ability of language models to perform complex, multi-step reasoning by effectively composing facts along reasoning paths?
What did the authors do?
The authors developed a novel training pipeline combining supervised fine-tuning and reinforcement learning to improve reasoning in language models using knowledge graphs (KGs):
Supervised Fine-Tuning (SFT): The model learns atomic facts and reasoning structures from question-answer pairs annotated with reasoning traces and KG paths.
Path-Aligned Reinforcement Learning (RL): Using Group Relative Policy Optimization (GRPO), the model generates multiple reasoning outputs per question, extracts reasoning triples, and receives two rewards: one for answer correctness and another for overlap with ground-truth KG paths.
Structured Prompting: A prompting strategy enforces separation between internal reasoning steps and final answer selection to improve learning stability.
What did they find?
The combined SFT+RL approach yielded significant improvements:
The 14B parameter model outperformed the SFT-only baseline on a challenging medical reasoning benchmark (ICD-Bench), especially on longer, multi-hop questions.
Achieved a 7.5% absolute gain on 4-hop questions and an 11.1% gain on 5-hop questions, demonstrating enhanced compositional generalization.
Maintained robustness under format perturbations and outperformed larger models like GPT-5.2 and Gemini 3 Pro on complex reasoning tasks.
Limitations include reliance on high-quality KG annotations and potential challenges in scaling to domains with less structured knowledge.
Why does this matter?
This work introduces a scalable and verifiable way to improve multi-step reasoning in language models by grounding them in structured knowledge graphs. By treating KG paths as implicit reward signals, models can better learn to compose facts into complex reasoning chains, which is crucial for applications like medical diagnosis, scientific research, and legal analysis. The path-aligned reward mechanism can be adapted across domains, paving the way for more trustworthy and capable AI systems that reason more like humans by leveraging explicit domain knowledge.
Key Points
Knowledge graphs can serve as implicit reward signals to guide reasoning in language models.
The proposed three-stage training pipeline combines supervised fine-tuning and path-aligned reinforcement learning.
Model improvements are especially notable on long, multi-hop reasoning questions in the medical domain.
The approach enhances compositional generalization and robustness compared to baseline models.