- TensorTeach's Newsletter
- Posts
- Can AI Think Before It Sees? How Reasoning Boosts Multimodal Understanding
Can AI Think Before It Sees? How Reasoning Boosts Multimodal Understanding
How reasoning steps reshape how models understand language and vision.
TensorTeach AI
October 07, 2025
Think Then Embed: Generative Context Improves Multimodal Embedding

Image from arXiv paper.
What’s the research question?
Can explicit reasoning steps improve the quality of universal multimodal embeddings that unify language, vision, and other modalities?
What did the authors do?
The authors introduced the Think-Then-Embed (TTE) framework, designed to enhance multimodal embeddings through explicit reasoning:
Reasoner component: Generates reasoning traces called Embeddings-Centric Reasoning (ECR) based on input queries and task instructions. The reasoner can be a large multimodal language model (MLLM) like Qwen2.5-72B used in a teacher-student setup, or a smaller model fine-tuned with ECRs.
Embedder component: Produces task-specific embeddings from the reasoning traces using lightweight models like Qwen2-2B or 7B, trained with contrastive loss to align queries and targets.
Configurations explored: (1) Large teacher reasoner without fine-tuning, (2) Fine-tuned smaller reasoner, and (3) Unified model combining reasoning and embedding in a single pass.
Evaluation benchmarks: MMEB-V1 and MMEB-V2, covering diverse tasks such as classification, visual question answering (VQA), retrieval, and grounding.
What did they find?
The TTE framework achieved impressive results:
State-of-the-art performance: TTE with a large teacher reasoner (TTE t) outperformed proprietary models on MMEB-V2.
Strong open-source results: Fine-tuning a smaller reasoner (TTE s) yielded a 7% absolute gain over recent open-source models.
Efficiency gains: The unified model (TTE u) combined reasoning and embedding in a single pass, reducing computational complexity.
Ablation insights: Explicit reasoning and intermediate Chain-of-Thought (CoT) traces significantly improved performance, especially for larger models.
Visualization: Embedding space analysis showed larger overlap between query and target embeddings when using TTE, indicating better alignment.
Why does this matter?
This work demonstrates that explicit reasoning can substantially enhance multimodal embeddings, which are crucial for tasks that require understanding and integrating language and vision. The flexible TTE framework allows leveraging large, powerful reasoners or fine-tuning smaller models for efficiency, making high-quality multimodal representations more accessible. Improvements in embedding quality directly benefit applications like visual question answering, grounding, and multimodal retrieval. Moreover, this approach opens new avenues for research on combining reasoning and representation learning, pushing the boundaries of how AI systems understand complex, multimodal data in real-world scenarios.
Key Points
Introduces the Think-Then-Embed (TTE) framework that combines explicit reasoning with multimodal embedding generation.
Uses reasoning traces (ECR) to improve alignment between language and vision representations.
Achieves state-of-the-art results on MMEB benchmarks, outperforming proprietary models and improving open-source baselines.
Flexible design allows for large teacher reasoners or smaller, fine-tuned reasoners, and includes a unified, efficient model variant.
MITS: Enhanced Tree Search Reasoning for LLMs via Pointwise Mutual Information
What’s the research question?
How can we improve the efficiency and effectiveness of reasoning path exploration in large language models (LLMs)?
What did the authors do?
The authors introduced a novel framework called MITS that enhances reasoning in LLMs through three key innovations:
PMI-based scoring: Uses pointwise mutual information (PMI) to evaluate the relevance of reasoning paths by measuring the mutual information between the question and each reasoning step, allowing incremental, stepwise evaluation without look-ahead.
Entropy-based dynamic sampling: Adjusts the number of candidate reasoning steps dynamically based on the entropy (uncertainty) of each step, exploring more when uncertain and conserving resources when confident.
Weighted voting: Combines PMI scores with prediction consensus through a weighted voting scheme to improve robustness of the final answer.
They applied beam search to prune less promising paths based on cumulative PMI scores, balancing diversity and quality of reasoning paths.
What did they find?
MITS significantly outperformed baseline methods across multiple reasoning tasks:
StrategyQA: 68.45% accuracy (vs. 47.34% for Chain-of-Thought)
ARC-Challenge: 92.55% (vs. 87.24%)
CommonsenseQA: 78.83% (vs. 66.67%)
It was also more computationally efficient, requiring only 64.41 seconds per instance compared to 2.75 seconds for Chain-of-Thought with self-consistency (CoT-SC). Ablation studies confirmed the importance of each component—PMI scoring, dynamic sampling, and weighted voting—highlighting their contributions to performance gains and efficiency.
Limitations include the need for careful tuning of PMI and entropy thresholds and potential challenges in scaling to even larger or more complex reasoning tasks.
Why does this matter?
This work advances the development of more intelligent and resource-efficient reasoning in large language models. By introducing a principled way to evaluate and explore reasoning paths using PMI and entropy-based sampling, MITS offers a scalable approach that can be adapted to various complex question-answering and reasoning tasks. Its modular design allows researchers to build upon this framework, potentially leading to LLMs that reason more accurately and efficiently in real-world applications such as education, decision support, and AI assistants.
Key Points
Introduces PMI-based scoring for incremental reasoning path evaluation in LLMs.
Uses entropy-based dynamic sampling to allocate exploration resources adaptively.
Combines reasoning path scores with prediction consensus via weighted voting for robustness.
Achieves state-of-the-art accuracy and efficiency on multiple reasoning benchmarks.
LaDiR: Latent Diffusion Enhances LLMs for Text Reasoning
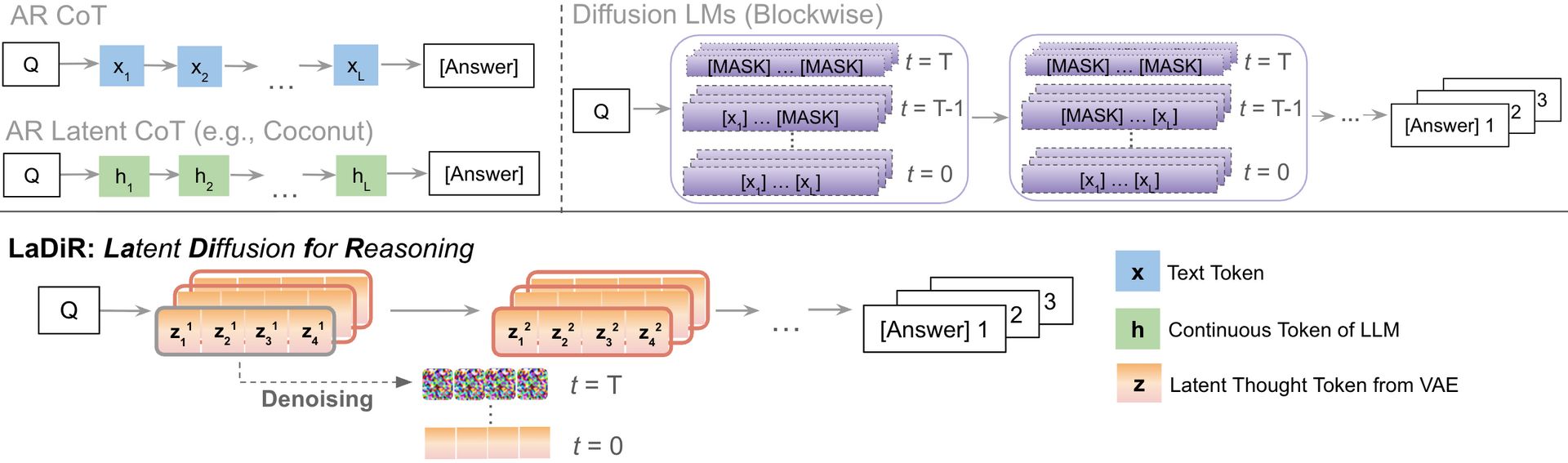
Image from arXiv paper.
What’s the research question?
How can latent diffusion models be integrated with large language models (LLMs) to improve reasoning capabilities and generate more diverse solutions?
What did the authors do?
The authors introduced LaDiR, a novel framework that combines latent diffusion with LLMs to enhance text reasoning:
Used a Variational Autoencoder (VAE) to encode reasoning steps into structured latent tokens, capturing semantic units of thought.
Initialized the VAE encoder from a pretrained LLM to learn compact representations of high-level reasoning.
Sampled latent tokens from a Gaussian distribution to introduce stochasticity and promote diverse reasoning paths.
Reconstructed reasoning text from latent tokens using a frozen pretrained LLM decoder, ensuring interpretability and semantic alignment.
Employed a separate reasoning model LLM with blockwise bidirectional attention to predict and refine latent tokens, enabling both local and global reasoning.
Implemented a diffusion-based denoising process that iteratively transforms Gaussian noise into coherent reasoning blocks, guided by a special token signaling answer generation.
Generated multiple diverse reasoning trajectories in parallel by increasing initial noise and applying a diversity gradient to push latent tokens apart during denoising.
Produced final answers autoregressively conditioned on the denoised latent tokens, allowing for holistic revision and exploration of different reasoning paths.
What did they find?
LaDiR achieved state-of-the-art performance on challenging reasoning benchmarks:
Attained an average pass@1 accuracy of 45.2% across in-domain and out-of-domain mathematical reasoning tasks, outperforming previous latent and autoregressive models.
In the Countdown puzzle planning task, showed over 30% absolute improvement in both Pass@1 and Pass@100, demonstrating superior global planning and diverse solution exploration.
Ablation studies revealed that:
Increasing initial noise improved both accuracy and diversity.
Moderate diversity guidance balanced exploration and stability.
Exhibited iterative semantic refinement, progressively correcting reasoning errors while maintaining coherence over long chains of thought.
Why does this matter?
LaDiR introduces a powerful new paradigm for reasoning in AI by integrating latent diffusion with large language models:
Enables semantic-level reasoning rather than just surface token manipulation, leading to more meaningful and interpretable solutions.
Promotes diverse solution exploration, which is crucial for complex problem-solving and creative tasks.
Offers improved robustness and generalization, making it suitable for applications like education, scientific discovery, and AI alignment where understanding and reasoning are critical.
Bridges the gap between traditional token refinement and deep semantic reasoning, pushing the state of the art in AI reasoning systems.
Key Points
LaDiR combines latent diffusion with LLMs to enhance text reasoning and diversity.
Uses a VAE to encode reasoning steps into structured latent tokens.
Employs diffusion-based denoising to generate coherent and diverse reasoning trajectories.
Achieves state-of-the-art results on mathematical reasoning benchmarks and puzzle planning tasks.
Making Mathematical Reasoning Adaptive

Image from arXiv paper.
What’s the research question?
How can large language models (LLMs) improve their robustness and generalization in mathematical reasoning tasks?
What did the authors do?
The authors introduced the AdaR framework, a novel approach to enhance LLMs' mathematical reasoning by synthesizing diverse, logically equivalent queries. Their methodology includes:
Data synthesis through variable perturbation: Keeping the core problem-solving logic unchanged while varying variable values within a controllable range (±α%).
Task decomposition: Breaking down complex problems into manageable, verifiable sub-tasks and converting logical text into executable code.
Generation of diverse query templates: Creating multiple variants of the same problem with different variable values to challenge the model.
Verifiable reward training: Using Reinforcement Learning with Verifiable Rewards (RLVR) to compare model responses on original and perturbed queries, encouraging adaptive reasoning.
Sanity checks: Ensuring generated data maintains correctness and validity.
What did they find?
The AdaR framework led to significant improvements in mathematical reasoning robustness and generalization:
Achieved an average gain of +8.50 points on benchmark tasks using only 9,000 synthetic data instances.
Enhanced model performance on both in-domain and out-of-domain tasks, demonstrating strong generalization capabilities.
Particularly effective when applied to models with strong initial mathematical reasoning skills, indicating a synergy between model strength and adaptive training.
The effectiveness of AdaR correlated with the model's baseline reasoning ability, suggesting it amplifies existing strengths rather than compensating for weaknesses.
Limitations include reliance on accurate problem decomposition and code generation, which may require careful engineering.
Why does this matter?
This work advances the development of more robust and adaptable large language models for mathematical reasoning, a critical capability for AI systems tackling complex, real-world problems. By synthesizing diverse, logically equivalent queries and training models to handle variations through adaptive reasoning, AdaR addresses key limitations of previous approaches that focused solely on outcome correctness. Its ability to improve performance with minimal data makes it a practical and scalable solution, paving the way for AI systems that can better understand, reason about, and solve mathematical challenges across diverse domains.
Key Points
Introduces AdaR, a framework for adaptive mathematical reasoning via query synthesis and variable perturbation.
Uses Reinforcement Learning with Verifiable Rewards to train models on diverse, logically equivalent problems.
Achieves +8.50 point improvement with only 9K synthetic examples, enhancing robustness and generalization.
Particularly effective for models with strong initial reasoning skills, highlighting the importance of adaptive training.
CoSMo-RL: Towards Trustworthy LMRMs via Joint Safety and Stability

Image from arXiv paper.
What’s the research question?
How can we develop Large Multimodal Reasoning Models (LMRMs) that are both safe and capable within a unified training framework?
What did the authors do?
The authors introduced CoSMo-RL, a novel training framework for LMRMs that jointly optimizes safety and reasoning capabilities through a two-stage process:
Stage 1: Supervised Fine-Tuning (SFT) on high-quality, structured reasoning examples that include multimodal inputs. Visual data are converted into symbolic representations to enable seamless reasoning with text.
Stage 2: Joint Optimization using a multiobjective reward function that balances four key components:
Visual-Focus: Attention to important visual elements.
Helpful: Producing safe, accurate, and informative responses.
Format: Generating structured outputs with intermediate reasoning steps.
Task-Aware: Aligning responses with safety, knowledge, and reasoning goals.
To ensure stable learning and prevent reward hacking, they employed the Clipped Policy Gradient with Policy Drift (CPGD) optimizer. Additionally, they used multimodal jailbreak data augmentation to improve robustness against adversarial and unsafe inputs.
What did they find?
The CoSMo-RL model achieved impressive results:
Attained an average safety rate of 85.2%, outperforming GPT-4.1 and other benchmarks on safety evaluations.
Demonstrated strong robustness against multimodal jailbreak attacks, reducing unsafe or adversarial outputs.
Maintained high performance on reasoning and instruction-following tasks, often surpassing larger proprietary models.
Ablation studies confirmed that each component of the joint training and reward design contributed significantly to the overall improvements.
However, the approach relies on high-quality structured reasoning data and careful reward balancing, which may require tuning for different applications.
Why does this matter?
This work advances the development of trustworthy multimodal AI systems by providing a scalable, unified framework that aligns safety with reasoning capability. By jointly optimizing these aspects, CoSMo-RL addresses a critical challenge in deploying LMRMs in real-world settings where safety and reliability are paramount. Its principles—staged training, multiobjective reward design, and adversarial robustness—offer a blueprint for future multimodal AI models that need to reason effectively while avoiding unsafe outputs. This progress paves the way for more dependable AI assistants, educational tools, and decision-support systems that can handle complex multimodal inputs safely and intelligently.
Key Points
Introduces CoSMo-RL, a joint safety and capability training framework for Large Multimodal Reasoning Models.
Combines supervised fine-tuning with multiobjective reinforcement learning and adversarial robustness.
Achieves higher safety and reasoning performance than several baseline and proprietary models.
Provides a scalable approach adaptable to different architectures and multimodal tasks.